The Broken Half of Interactive Programs
While most front-ends today have largely agreed on the design of the rendering subsystem, we seem to be grappling with design of the interactive subsystem.


We still don't know how to structure interactive programs.
In the last couple of years, web front-ends evolved quickly to converge to a design with two subsystems that depend on each other. The first subsystem renders components in a view as a pure function of application state. The second subsystem leverages a state manager and some way to deal with side effects to provide interactivity.
This interactivity not only responds to user input, but also to network messages. While most front-ends today have largely agreed on the design of the rendering subsystem, we seem to be grappling with design of the interactive subsystem. We devise different ways to deal with side effects without clear tradeoffs. We can't decide where state should live, and how to manage state changes in a flexible way.
What should the the interactive subsystem of the program look like to keep the render side of the loop functional?
If you have any insight into this, email me or tweet @iamwil.
The evolution of front-ends
Front-end architecture for the web has evolved quickly in the last couple of years. Early on, front-ends weren't much of a program. It was a hodge-podge of event handlers, and as the front-end grew in size, the corresponding complexity grew even faster. It became a rat's nest of dependencies of a component's state with incoming changes from both the user and the server.
This complexity only worsened with the desire to give users a low latency experience. To that end, we now build Single Page Apps, which manage their state in addition to handling user events and server updates. It became hard to keep views consistent both internally and with the state on the server.
We needed a way to organize the front-end programs.
To that end, circa 2010, we've had a slew of front-end frameworks such as Backbone, Knockout, Ember, and AngularJS, all with differing opinions on the topic. [1] Around 2013, React introduced a simplification of front-end programs using functional concepts and the virtual DOM to bring immediate-mode rendering to web developers. And in 2015, Redux introduced a reducer as a sequential message processor to manage state changes.
While we've had other libraries since then to challenge React and Redux, we seemed to have stabilized on this architecture that pairs functional rendering with one-way data flow with a managed state/effects. These two halves of the architecture are tied end to end to form a core loop of our application that makes it easier to reason about.
The Core Loop
The core loop of most front-end architectures looks something like this:
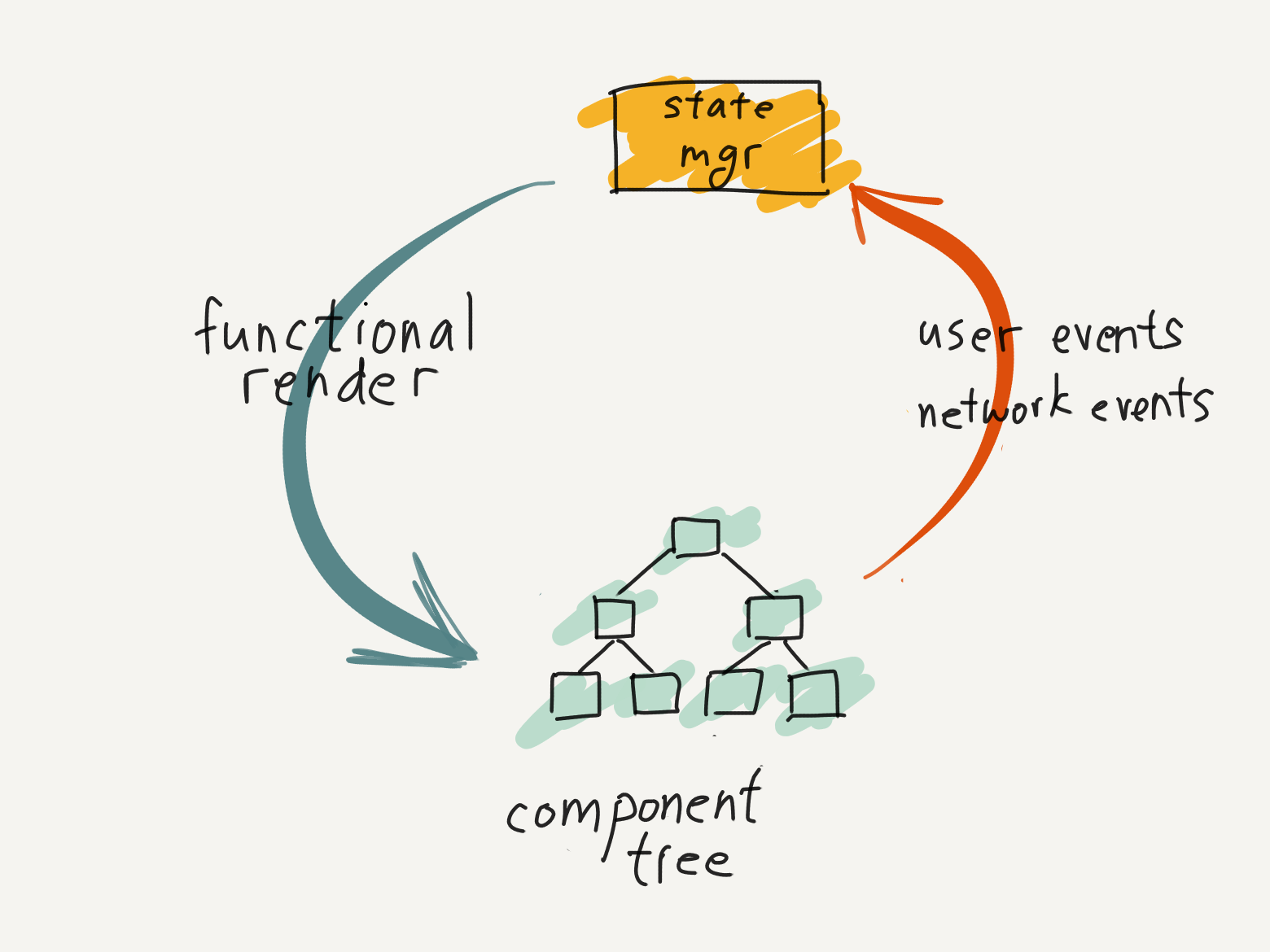
- One-way data flow from the state at the top of the application down to the rendered components. [2] Components are a pure function of state.
- User actions are handled in the component rendering the UI. The handler emits messages to the state manager. The state manager changes the state based on the message.
- State changes trigger a re-calculation and re-rendering of the components.
Hence, the core loop of the application is easy to understand. On one side, application views are rendered as a pure function of the state. We can call this the render side. On the other side, user interactions invoke state changes that trigger re-renders. We can call this the interaction side.
It's worth noting at this point this design has analogs in other ecosystems. In enterprise back-ends, there's a design pattern called Hexagonal Architecture (or more aptly named: "Ports and Adaptors"). It makes the general recommendation: write applications with a functional core, and an imperative shell.
"Functional core, imperative shell" encourages programmers to build the core of a program with pure functions until the point where the program needs to interact with the outside world. This happens at the boundaries of the program, such as user interactions, databases, and the network. At that boundary, use an imperative shell to manage these side effects.
We see web front-end applications converging on the same design. Let's look at each side in turn, though we'll spend more time on one than the other.
The Render Side
On the render side, we can see it has an analog in games. Before React, front-end programmers had to maintain both the application state and the DOM state in sync. Syncing these two states can be hard to do consistently and is error-prone. It contributes to the complexity and can introduce view consistency bugs. React introduced immediate-mode rendering to web developers without calling it that.
In games, a frame is rendered entirely from the game state. No rendering results from previous frames are used to render the current frame. In other words, rendering is a pure function of state. While this can make a rendering API more low-level, it frees the programmer from syncing the application state with the renderer's state.
The advantage of this architecture is that the core is much easier to reason about and test. Pure functions are only affected by their inputs. And one doesn't need to mock up a graph of objects just to test a pure function.
… Because the problem with object-oriented languages is they’ve got all
this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
- Joe Armstrong, creator of Erlang Programming Language
The front-end library and ecosystem in Javascript seemed to have converged on a functional design on the render side. I won't expand on the benefits of functional programming here, as that is covered elsewhere. The current design issues rest on the other side of the core loop: the interaction side.
The Interaction Side
On the interaction side, the story is a little bit more complicated. On this side, a programmer has to contend with both user input and network comms with the server, both commonly regarded as side effects.
While pure functions are easier to reason about and test, it's impossible to build useful programs with just pure functions. Many useful programs are interactive programs that need to respond to user input or the outside world through the network. That's why we have an interaction side of the loop.
But by their nature, handling user interactions and network responses are not pure functions; the output of the side effects depends on inputs that are outside of the program, and hence outside of its control. To keep the useful design of a pure functional core with interactive elements, we're forced to push all side effects to the boundaries of the program. Then the question remains, how to best handle the impure interactive elements? This is where front-end programs and the larger functional programming communities differ.
Effects with Monads
In contrast to enterprise back-ends that use the hexagonal architecture, pure functional languages like Elm and Haskell, a program cannot explicitly execute side effects. When the pure functional core runs up against the boundary of the program, it uses monads and monad transformers to compose these side effects together. The composed side effects are queued up for the underlying runtime to execute. In Elm, they're called commands, and in Haskell, they're called I/O monads. One can think of it as using commands and I/O monads to tell the effects manager in the runtime what side effects to run.
On one hand, effect managers have the advantage of keeping the rest of the program purely functional and decoupling the event handler from the state manager. However, control flow is now harder to follow and no longer explicit. Typical stack traces are useless here, and we'd have to use other tools to trace a message across the effect manager to its corresponding state update. To complicate tracing, a single event can emit one or more messages for state updates.
Effects with Algebraic Effects
Monads and effect managers aren't the only solution to dealing with side effects at the boundaries of a program in a pure functional language. Experimental languages such as Eff and Koka both feature algebraic effects as a way to manage side effects.
An algebraic effect is like a resumable exception. Instead of using the underlying runtime to execute side effects, the programmer implements the side effect in what looks like a "catch block". The side effect can then be invoked anywhere in the "try block", even if it's invoked deep in the call stack. An invoked algebraic effect will jump back up to the "catch block" to execute the effect, and then resume back where it was invoked after the effect has been completed.
The only design I know of that remotely leverages algebraic effects on the interaction side are React Hooks. Unlike Redux and The Elm Architecture (TEA) which keep all application states at the root of the component tree, hooks allow us to choose at which level state can live in the component tree. This can be useful for scoping view state, such as which dropdown was selected, to its local component tree. If the view state needs to be seen across sibling components, we have the option of pulling it up to the lowest common ancestor. Hooks also keep the view and relevant state together, which is easier than tracing messages across the effects manager to discern how a message would change the application state.
Effects with Linear Types
Lastly, a less well-known method is using linear types to manage side effects.[4] Linear types are a type system that restricts a program to only a single reference to a variable. Side effects, such as network fetches, rely on the state of the world for their output. Since we can't rewind and rerun the world, it's impossible to do a network fetch twice and guarantee the same output as a pure function. Hence linear types are a way to constrain the programmer to make sure a side effect is never run more than once.
I don't know of any front-end interaction side design that leverages linear types. Perhaps there are Rust GUI libraries that would count. If you know of any with an interesting design, let me know.
Much of the effort from functional programming has been on how to deal with side effects at the boundaries. But for the design of the interaction side, there are other things to consider. Let's explore a couple below.
Where should state live?
As mentioned earlier, Redux and TEA keep a single global state at the root component, with a single reducer to manage state changes. Global state is possible because writes are sequenced linearly by the underlying runtime, and we're not subject to unpredictable data races.
On the upside, we can see all our state changes and updates in one place, the reducer. The reducer is usually implemented as one big case statement, but it should be seen as a finite state machine (FSM). With it, we get the advantages of an FSM: we can enumerate all good states and their transitions and make impossible states impossible.
Another upside of keeping all application states global is that it becomes trivial to implement infinite undo and time-traveling features. However, I've rarely seen web apps leverage this. This is probably because outside of database-less web apps, this requirement would cascade supporting undo all the way into the database, which is no easy thing, as most databases mutate in-place.
The downside is that it's hard to get the granularity of the state updates correct. If it's too fine, the event handler may need to generate many messages for a single user action, which makes it harder to trace and debug. If it's too coarse, the programmer may find duplication between the different state changes in reaction to messages. In addition, with actions that fetch data over the network, there often needs to be intermediate states that represent the state of data while in transition and error to account for network failures. And while Redux has the concept of sub-reducers that compose, in practice, I found it cumbersome to move state changes in reducers up and down to keep the code organized and in lock step with my current understanding of the domain problem.
Additionally, an application may need to keep two different types of state, a domain-model state (i.e. list of todos that have been done) and a view state (i.e. the selected dropdown in a list of todos). In an application with global state, reusing the same component in another part of the app requires adding a new global view state. This is extra bookkeeping a programmer would need to keep track of. Hooks are better in this regard by bundling the view state of a component entirely within the component. Reusing a component involves just using the component, and not about coordinating the global view state with the component it references.
How should state be referenced?
A fundamental assumption of React is that the structure of the state tree largely matches the structure of the component tree. But this isn't always the case. In an illustration app (like Figma), the state of a shape (such as its x, y coordinates) has a single source of truth. However, that state is being referenced in the following sibling components: in the main canvas to draw the shape, in the right sidebar to show its relation to other components, and in the left sidebar to display its properties.
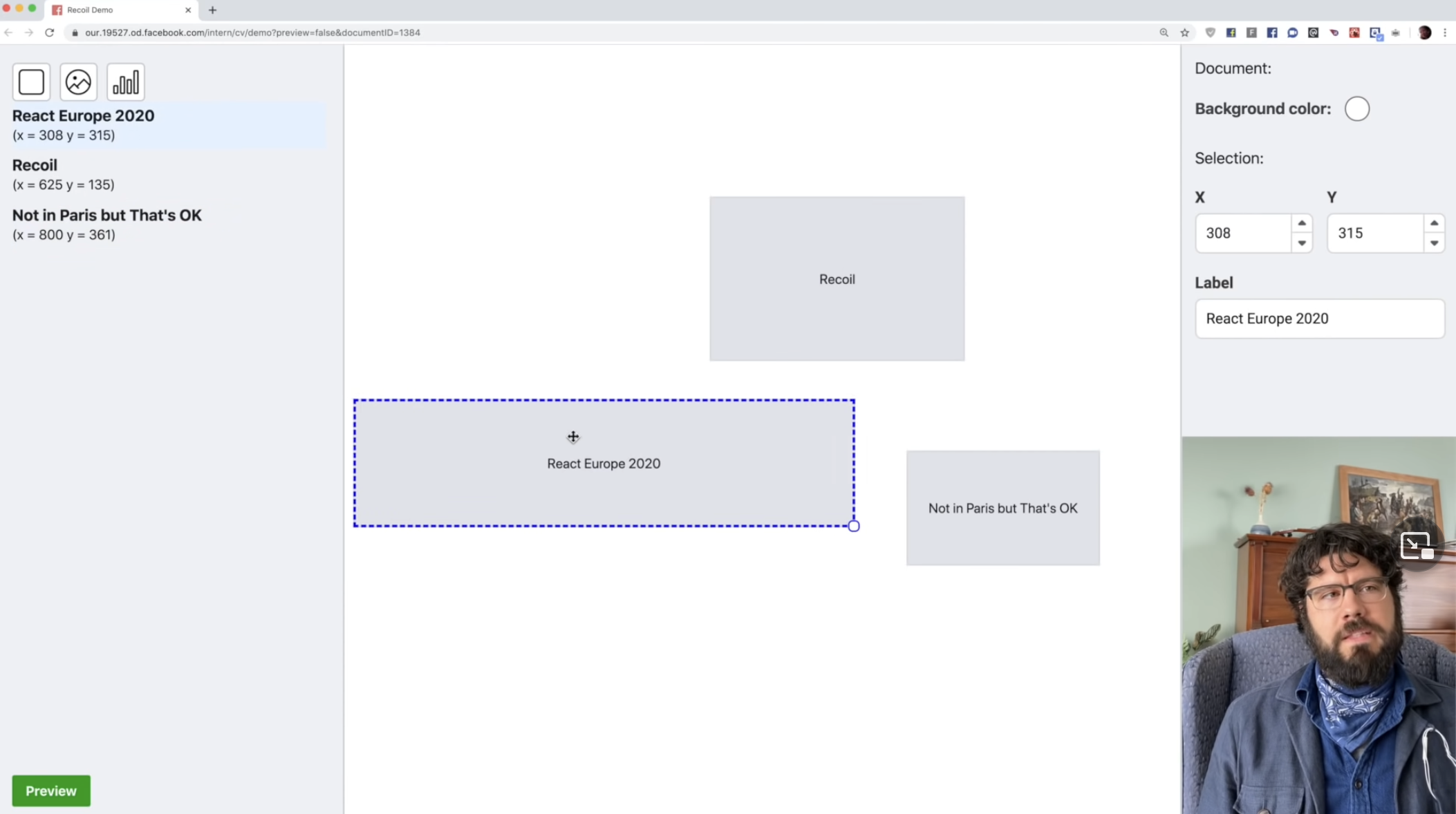
In a case like this, the recommendation is often to pull the shape's state up to the first common ancestor between all the siblings. However, in React at least, this has the issue of forcing unnecessary re-renders in sibling components that don't use the shape state.
Recoil is another state management library from Facebook that tries to solve this problem by introducing querying of the state, which decouples the shape of the data from the shape of the component tree. Solid.js claims to only render all components once, but rerun all its hooks, so it may not have this problem.
What if we make time explicit?
What if we make time explicit? If we treat user interactions not as a lone event in time, but as a signal of user interactions over all time? That way, we can treat it as an immutable value that we can plug into pure functions.
Well-read readers would recognize this is what functional reactive programming (FRP) poses as a solution to structuring the interaction side of the core loop. [3]
On paper, it doesn't sound like a bad idea. However, we've done that experiment once. Elm started as a language embracing FRP, but decided to say farewell to it. It turns out TEA killed off FRP in the name of ease of learning and understandability. That may either be an indictment of the method or that most programmers weren't conceptually ready for it back then.
But perhaps it just needs to be introduced in a different guise. Solid.js uses a hooks-like API for its state, but instead of calling it createState, it's called createSignal.
How should state be updated?
What if state was versioned instead of updated? States would be considered immutable and append-only. We could treat the entire future and history of the state as a value, where previous versions are immutable and future versions are also immutable, but just not yet revealed to us.
At first thought, immutable state should make renders faster, because it'd be easier to compare equality to decide whether a component depending on a state needs to re-render or not. The immutable values could also be shipped around and make it easier to communicate with remote resources like the server's database. However, it also means that state would need to be garbage collected when old states are no longer being used or referenced, and this might impact performance.
However, as I describe this, it sounds suspiciously like FRP, so I might have to make a separate post to figure out the implications.
What about in games?
As a passing thought, what do games do? They're the most interactive of all programs, to the point they're considered a medium.
But as far as I can tell, they don't do much hand-wringing. They just mutate state and be done with it. While the rendering system is a pure function of state, that's largely handled by the game engine. Most game code deals with the state imperatively, and I don't know of any games that are written in a functional language. However, the best game programmers understand the value of a functional style in their programs, so at least there's some agreement on the "functional core" part.
How do games manage updating game state in a manageable way? I do know that finite state machines are commonly in use. And state can get complex with open world systemic games, where the desired property of the game is a combinatorial explosion of behaviors from a combination of game mechanics, such as cats vomiting in taverns in Dwarf Fortress.
But overall, I'm less familiar with what developers typically do here, the problems they run up against. Let me know if you know.
Discussion
In summary, it seems like the properties we'd want in the interaction side are the following:
- View state and its transitions should be bundled by default with a component to make it easier to reuse the component. The view state and its transitions can be separated from its default component if necessary to make variations, such as dropdowns with or without search.
- Domain-model state should be accessible to any component but scoped if necessary to avoid re-rendering.
- State managers are finite state machines. It should be easy to group states and transitions for reuse and composability. It should be just as easy to break a grouped state into its component states and transitions to refactor.
- State management should include pre-built states and transitions to handle network fetches, waits, and failures.
- User actions and server pushes should be traceable from the event emittance, through the application state changes, all the way to the re-rendering of the components.
Taken together, I wonder if an in-memory database with some type of restricted update semantics would be what I'm looking for.
Do these problems and properties resonate with you? Are these systemic problems that you see in front-end libraries and architectures? If you have thoughts or insights, let me know.
Thanks to Sri Thatipamala for reading drafts.
In linear logic, variables of a non-linear type can be coerced to a linear type (dereliction). Harrington phrases it well: in linear logic, "linear" means "will not be duplicated" whereas in uniqueness typing, "unique" means "has not been duplicated".↩
- from Uniqueness Typing Simplified
Photo by Vanessa Loring



