Persistent Data Structure Redux


This is a review of all the resources I found and learned about persistent data structures in the course of looking for a solution for maintaining state.
Complexity from maintaining state
One of the hard things about programming is how to maintain and manage state, especially at scale. In interactive programs, this manifests itself as all the bookkeeping required to fetch data from remote APIs, send and retrieve data from the database, and maintain the state of the view not dependent on the data (such as the state of a pull-down or current animation state of a UI component).
In my search for prior art on the topic, I came across Datomic, a functional immutable database. It's a database you can treat as a value in the functional sense, rather than a "place" where you can fetch and update data.
Why is this a problem? It turns out that much of the complexity in our modern web systems stems from the problem of maintaining state "over there". This phenomenon is outlined nicely in Juan Pedro Bolivar Puente's talk.
When data can change out from under you after you read it, there's a lot of work to compensate for it. Without that work, it's hard for humans to reason about, because we tend to think and reason in a sequence where only one thing happens at a time. So we just start adding the complexity, thinking that there isn't a way out.
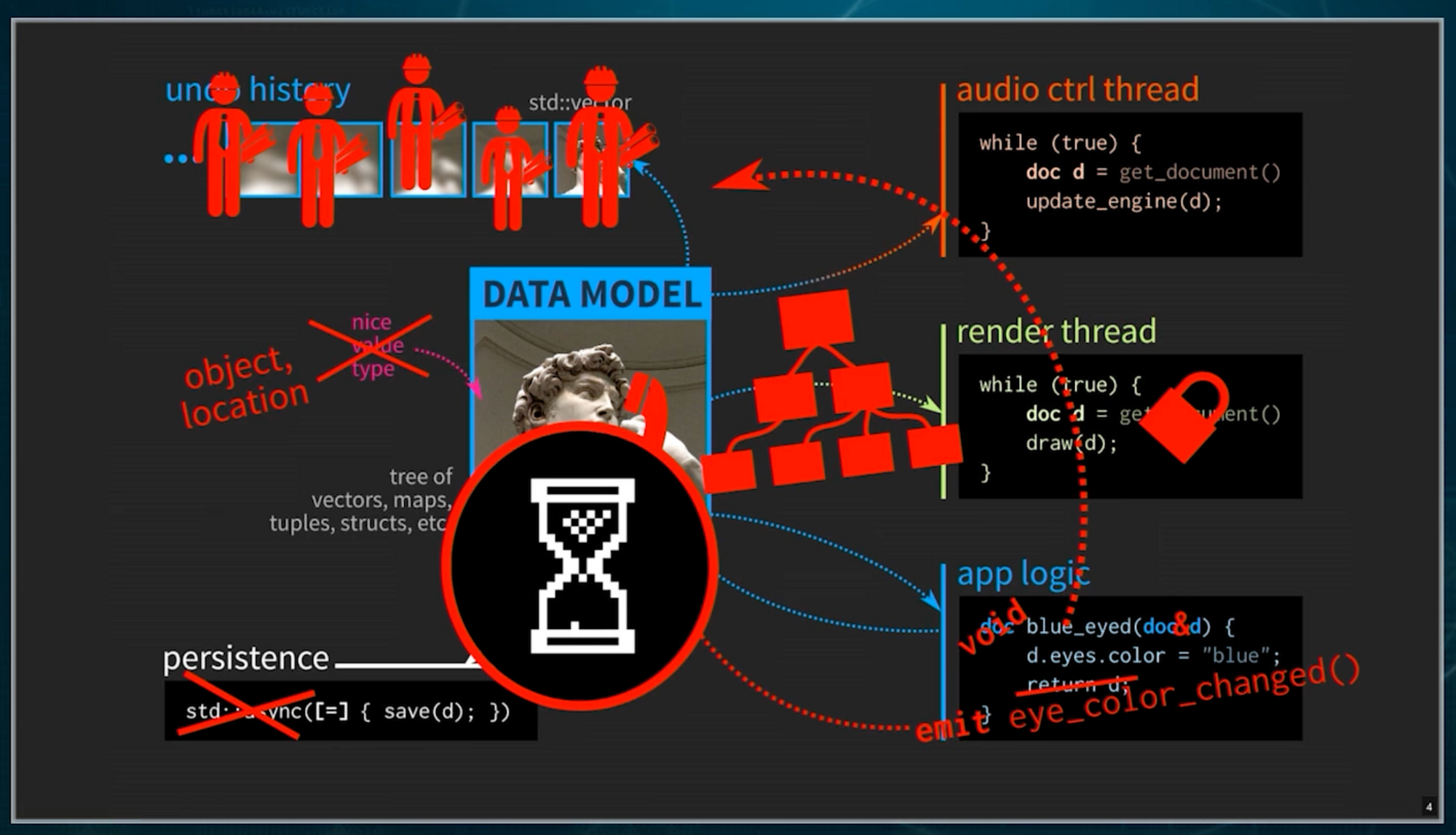
Immutability is the star
Some people get hung up about types in functional programming when immutability is the star. Immutability guarantees that something won't change out from under you after you read or write it. This single thing simplifies the architecture of our systems drastically when we can swing it.
But what about databases? Could databases, explicitly used for maintaining state, be used as a value? Yes, if the database never ever deleted a record, and updates are actually just writing a new version. That's Rich Hickey's insight when he built Datomic.
What would it take to build your own functional immutable database? You need your own persistent data structure.
Persistent data structures
Persistent data structures are immutable. Once written they can never change. Once you read it, you're guaranteed that some other thread isn't going to come around and change it. Any updates to the persistent data structures actually amount to creating a new version with the update, so any older versions stay intact.
Now, there's no coordination required from reading data, which simplifies the problem of reading data. Writing data also doesn't require coordination if a single source of truth doesn't need to be maintained. But if you want everyone to agree on a single view of truth, then writes typically needs to be serialized.
One objection to this scheme may be that it would take up too much space. In practice, each version of the data uses structural sharing. That's where new versions of the data structure reuse data that didn't change from the previous version.
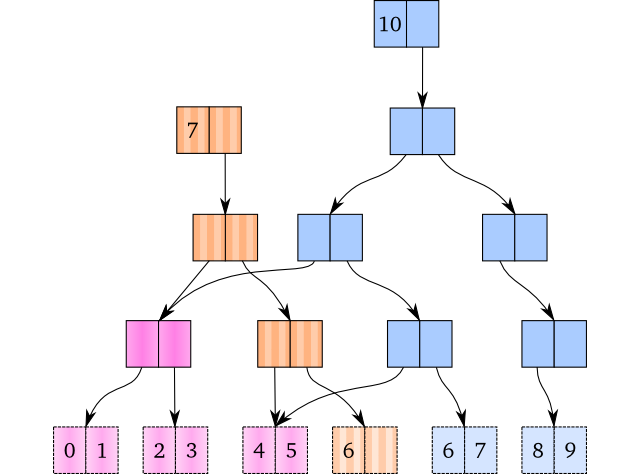
Chances are you use version control software like Git, and it uses a very similar idea. Every commit structurally shares the files that didn't change from the previous commit.
I initially started looking at surveys and talks on persistent data structures.
- Persistent data structure survey
- MIT 6.851 Advanced Data Structures Lecture 1 [lecture and note list]
- Okasaki's Purely Functional Data Structures
I found them to be rather broad, so I started looking at specific tree algorithms. A good place to start for any database retrieval algorithm is B+ Trees.
I thought it was a good starting place to implement a B+ Tree in Rust to get familiar with the language [1]. Turns out typical data structures such as a linked list are bad starting points for Rust. These data structures usually have two pointers pointing at the same piece of data, which violates the basic ownership enforcement required in Rust programs. This required me to unlearn many of the things I learned when I learned C. The following were good reads on this topic:
After reading about the weaknesses of B+ Trees, and looking through a bunch of others, I happened upon the Hash Array Map Tries (HAMTs) by Phil Bagwell. I saw an implementation of this in the im.rs library. The confluence of im.rs, Bagwell's work on Ideal Hash Trees, and Clojure's own implementation lead me to Relaxed Radix Balanced Tries (RRBTs), a variation on the Radix Trie.
Radix Tries structures itself after the key, leading to large fanouts, and keeping all data at the leaves of the trie. By keeping the trie balanced as an invariant, we can achieve O(log n) lookups.
Clojure uses some variant of this, which is well described by L'Orange in his blog post series, as well as Krukow's posts.
- Understanding Clojure's Persistent Vectors, pt. 1, pt. 2, pt. 3
- Understanding Clojure's Transients
- Persistent Vector Performance Summarised
- Understanding Clojure's PersistentHashMap (deftwice...)
- Assoc and Clojure's PersistentHashMap: part ii
But specifically, RRBTs I found three main sources in Bagwell, L'Orange, Stucki, and Bolìvar Puete.
- RRB-Trees: Efficient Immutable Vectors
- Improving RRB-Tree Performance through Transience
- RRB Vector: A Practical General Purpose Immutable Sequence
- Turning Relaxed Radix Balanced Vector from Theory into Practice for Scala Collections
- Persistence for the Masses: RRB-Vectors in a Systems Language
- CppCon 2017: Juan Pedro Bolivar Puente “Postmodern immutable data structures”
- 🐙🐱 Magnap/persistent-vector-rs
- 🐙🐱 hypirion/c-rrb
I found that I had to piece together information from all of these sources to figure out an implementation. But once it's in your head, it's actually pretty intuitive. The most complicated method to implement is concatenation, as it has to keep a relaxed version of its invariants to guarantee its properties. But with both `concatenation` and `split`/`slice` you can implement insertion.
In the process of doing the implementation, OpenAI released ChatGPT. I tried using it to help, as an experiment.
I asked it to explain and convert the pseudocode to Rust. It was a mild success. While I couldn't use the code it generated, the comments and code in Rust made it more clear what was going on.
I've also used ChatGPT as a sounding board to help me understand papers. Here, I ask it to convert pseudocode to Rust and ask it to explain every line to me. pic.twitter.com/SaqoQnS16F
— Wil Chung (@iamwil) December 8, 2022
Defaults matter
Javascript has a bunch of immutable libraries, but to my knowledge, it's not overwhelmingly popular. I think languages like Clojure that build it in as a default have a leg up on other languages.
Immutable data structures should be the default in a new modern programming language, and mutation of state should be an intentional act by the programmer. The advantage of immutability everywhere you can swing it, even in places you didn't think you could before should be able to create wins in reducing complexity in our software.
[1] I decided to go with Rust instead of Zig, since I was a new systems programmer. I figured having the guard rails would really help. Turns out Rust is a really complicated language.



