Destroyed at the Boundaries
Shared mutable state invites complexity into our programs. Programming languages help with this complexity inside a program, but not across network boundaries between programs.


Today’s web developers are distributed systems engineers, they just don’t know it yet. And unfortunately for them, most languages and tools fail programmers exactly when they need them most: in a world full of network boundaries.
Programming languages help with complexity stemming from shared mutable state inside a program, but not across network boundaries between programs. This is especially true of web apps, commonly with two network boundaries. [1] We could initially ignore it, circa 2007 by pushing shared state down into the database and treating browser pages as a pure function of state. But today with single-page apps keeping state, serverless cloud functions, and microservices backends, this is no longer the case.
I think much of the complexity can be tamped down if we had practical abstractions across these network boundaries. What should they look like? Or are network failures an inescapable complexity that we can't abstract over?
If you have any insight into this, email me or tweet @iamwil.
The network boundary
Let's pick on pure functional programming for a second. It deals with shared mutable state by banishing mutable state within a program altogether and pushing it to the edge of the program. Then I/O monads and algebraic effects populate the edges to keep out the mutable world.
However, pure functional programming has nothing to say about composing programs across this network boundary. [2] And it's not just pure functional programming. Most languages and paradigms address complexity stemming from shared mutable state within a program by constraining the context in which state is used.
For example, Rust's smart pointers and ownership rules make it explicit who can update a variable at any one time. Clojure's atom/ref/var/agent reference types achieve a similar end along different dimensions. The Hexagonal Architecture preaches a pure functional core with an imperative shell. [3] None of these address the composition across the network boundary.
While Java (along with its JVM ilk, Scala and Clojure) are often used to build distributed systems and web apps, these languages and their ecosystem of libraries also make it apparent when you're reaching across the network to another program. As for Javascript, the most popular language for web apps, it has little to no support across the network boundary either, needless to say. [4]
The only languages that directly address this are ones that were designed to build distributed systems from the get-go. Erlang/Elixir leverages the actor model and message passing over the network. Pony uses a type system to check that code is dead-lock and data-race free. Unison sends functions across the wire instead of data, because Unison code is immutable and content-addressable. However, these languages are currently not particularly popular for building web applications. [5]
What is it about web applications that makes them susceptible to this network boundary problem? Simply put, web application workloads are dominated by I/O, disk, and network, rather than the CPU. For any particular CRUD app, most of the work is mapping data from structure to structure, and waiting on the network. We used to be able to ignore the problem of shared mutable states across network boundaries by making prudent architectural design decisions.
Around 2007, web developers could ignore the problem of shared mutable state in the system with server-side rendered web architecture. On the back-end, you could scale by making the application servers as stateless as possible, and pushing that state down into the database. As a result, we delegated all the hard parts of concurrent programming to the database, which they already specialized in. On the front-end, the view for an endpoint was a pure function of the state of the database. There were no inconsistencies in the page because like immediate-mode rendering, we throw away the entire page and request a new one when the user navigates away from the page.
But today, web developers can no longer ignore the shared mutable state across network boundaries. On the back-end, we have microservices architecture that complicates it into a distributed system. On the front-end, we've started constructing thick clients on the browser that manage state of their own, under the banner of more responsive/low latency apps. No longer a pure function of state, front-ends are rife with inconsistent views and introduce complexities like hydration. [6]
The composable properties offered by powerful abstractions in modern languages, such as ownership, immutability, monads, algebraic effects, linear types, etc. help manage the complexity of shared mutable state within a program. And yet, this composability all get destroyed at the boundaries of the program. We still haven't figured this out, even though our software systems are full of network boundaries.
The Two Boundaries
Most web apps have two major boundaries: the browser/server boundary and the server/database boundary. Let's go over the current design problems with these two boundaries.
The Browser/Server Boundary
On this network boundary, the latency is higher and less reliable. The question is: how to send code and state over the network to deliver a fast-loading application and keep a consistent view with new user input and events, even in a loss of connectivity?
For client-side rendered apps (single page apps), most of the current activity in the space is centered around state management in the browser. However, these libraries are largely unopinionated about how you fetch and sync the server state with the client state. [7] Some sort of async effect handler is provided, and it's up to you to manually fetch data from a server endpoint and the method to update the application state from the data received from the server. [8]
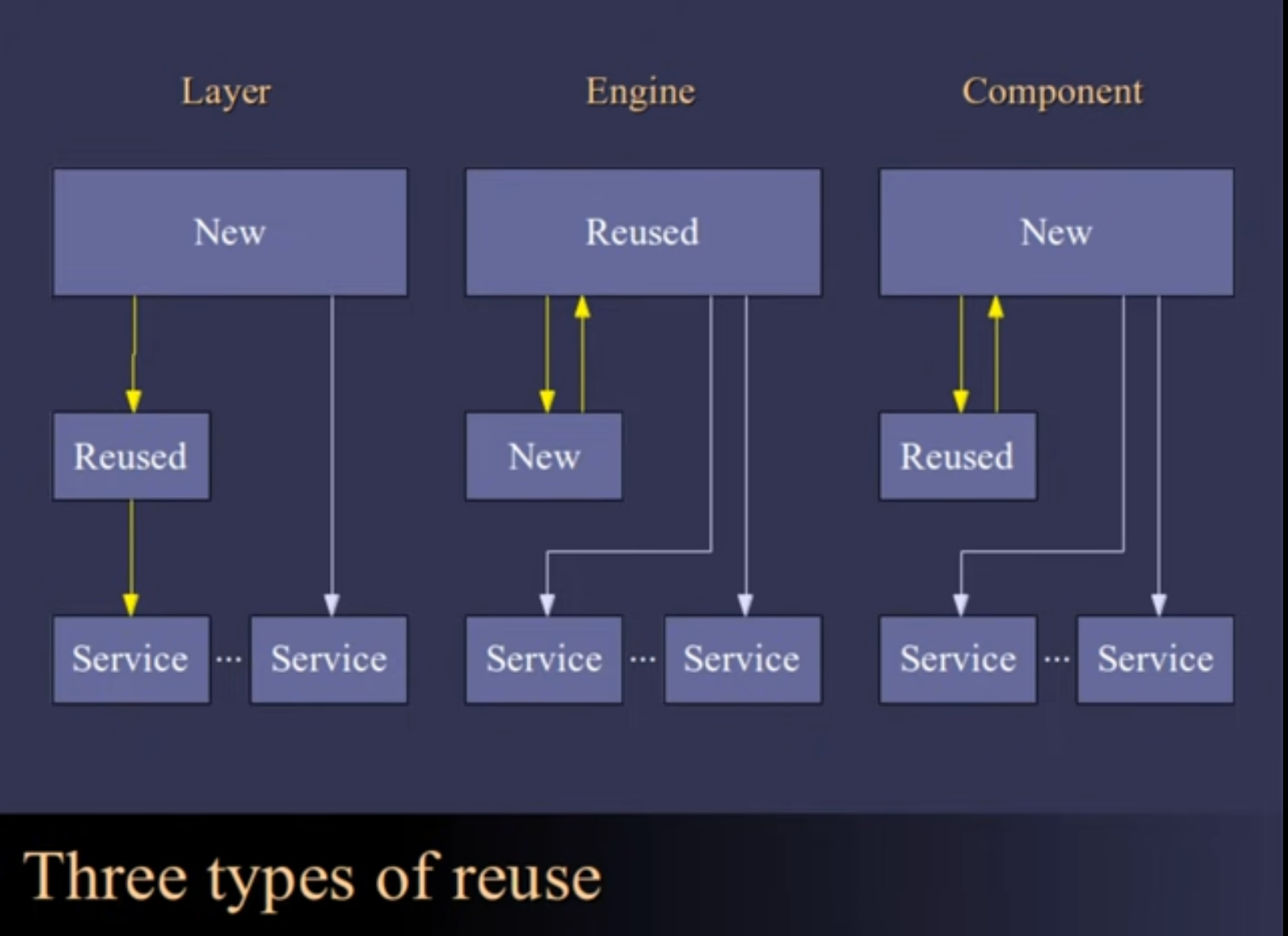
There are a few libraries that specifically focus on this problem, such as React Query and Hasura Subscriptions. Both provide functions to tie the fetching of data, displaying of data, and mutation of data together, so that there's deep integration between all three stages to keep them in sync. However, the API is more like the engine type of reuse, where it's the library that's in control, and you're just filling in the blanks. This can be problematic if you ever need to do something the engine doesn't provide. They don't provide compositional properties over the network boundary.
 |
|---|
On the other side of this same boundary, server-side rendering advocates have long considered client-side rendered apps as complex and slow-to-first-render. Instead of sending data from the server to the client for it to render, the server renders a partial view of the data and sends it over to the client. The client wouldn't do a full page reload, but take the partial view and insert it into the current page. [9] The initial load is quick, because it's a thinner client. And the user still experiences an app that doesn't refresh on every action, but now every action is subject to a round-trip latency.
The Server/Database Boundary
No matter how well you constrain mutable state in your programming language in a web app, you'll need to deal with the database: it's the ultimate global shared mutable state.
On this network boundary, the data is often "over there" with the database and the business logic is on the application server "over here". The question is: do you bring the code to the data or the data to the code? Current designs often choose the latter, which means how the data is structured, represented, and accessed will affect systems on both sides of the boundary. This wouldn't be an issue if both sides agree, but oftentimes, they don't. How do we resolve this tension?
Traditionally, databases weren't designed to run arbitrary business logic–we don't move the application code to the data. Instead, we move a subset of the data to the application server, by sending the database a query, effectively short declarative programs to get a subset of the entire data set.
Databases are also typically designed with in-place updates of data, which Rich Hickey calls Place-orientated programming (PLOP). [10] PLOP means that you're if you're reading data, some other participant might have updated it since you last read it. Therefore, reading values for consistent views and incrementing counts require coordination between participants, which complicates the client.
As a consequence of these design choices, we're wary of making too many small requests due to the overhead of making round trips. It's up to the client to now batch up queries, which also complicates the client. For example, when implementing a GraphQL server, a front-end request can traverse any number of tables and microservices. It's up to the server to batch up those requests to keep the overhead for a request low.
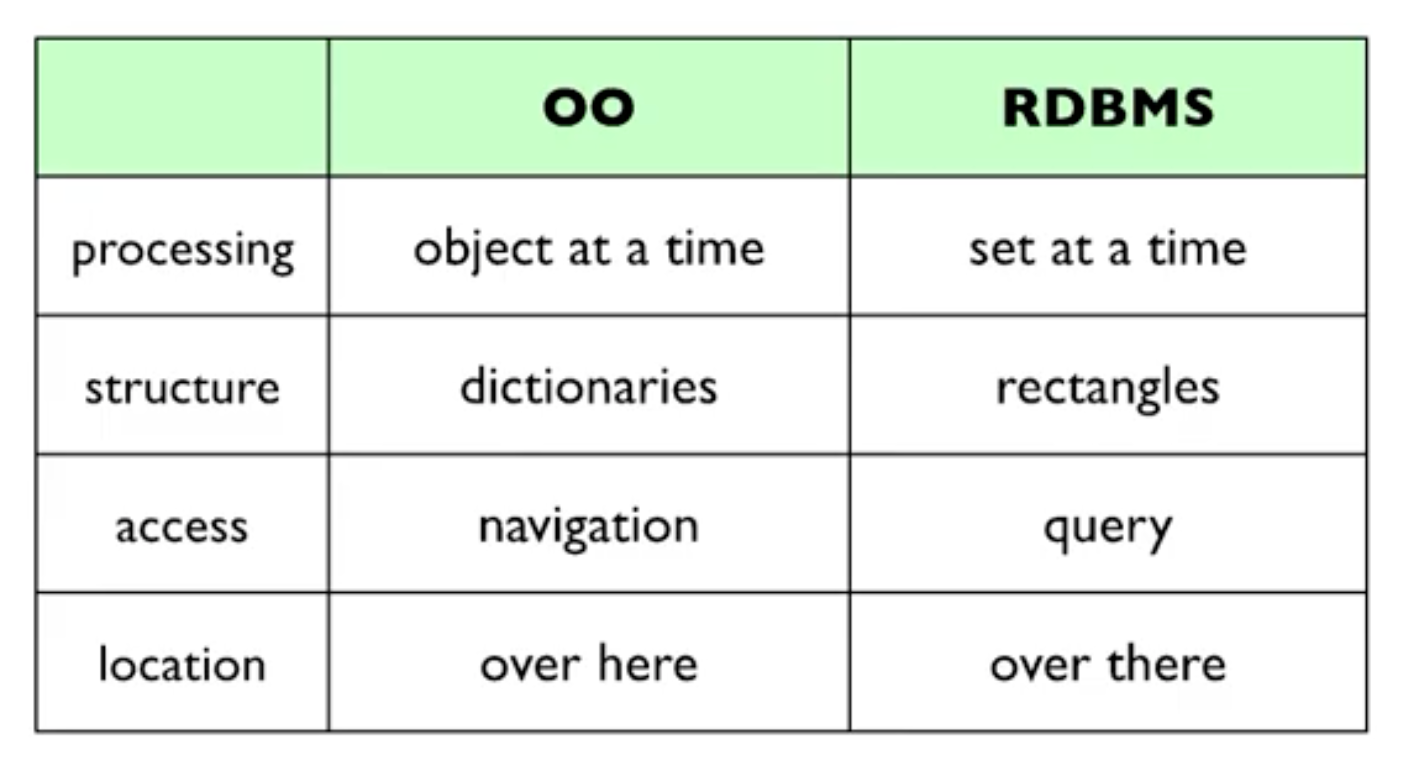
Because we typically bring the data to the application code, the way it's represented and structured couples software systems on each side of the boundary. Databases often choose a set and relational representation of data, because that aligns with their goals of data storage and access. On the other hand, application servers tend to process data as objects and dictionaries, as mainstream languages tend to be structured around object-orientated programming. This tension results in friction and complication at this network boundary called the object-relational impedance mismatch. [11]
A short summary of the mismatch is summarized in the table below.
 |
|---|
We've tried to solve this with object-relational mapping (ORM) libraries, but often to no avail. [12]
Does it need to be that way? What if we moved the code closer to the data instead? It's typically big data systems that move the code to data, but there do seem to be some applications that make the choice of putting business logic in the database as stored procedures. However, this architectural choice currently also has friction as it often doesn't work with other developer tools and workflow, like version control. In addition, scaling out via replicas introduces consistency issues.
Does the data need to be updated in-place? What if data is immutable and append-only? Then, reads can be done without coordination with other participants. Favoring immutable data has seen success in a variety of software, such as React, immediate-mode rendering, Clojure, Kafka, and others. It stands to reason, that immutable data would find a chance for success here too.
At this point, I'm not advocating for any particular solution. In the design space of cutting a boundary between systems, we seem to be making the decision manually for each application. The place where we make the cut has significant design implications for the rest of the system, and perhaps we can rethink where that boundary is cut, and whether we need to do it manually at all.
Composition across the network boundary
How do we compose over the network boundary? Are the eight fallacies of distributed computing impossible to abstract over because of its inherent complexity? Or is it akin to memory management, where we insisted on doing it by hand until the abstraction became so good that we couldn't justify it any longer for large swaths of programming domains?
Like all beginner optimists, I suspect we should be able to. TCP/IP abstracted the network, so data looks like it came in order. HTTP request/response abstracted over TCP/IP, so it looks like servers are engaged in a conversation. When it comes to distributed computing, however, we've taken abstractions that work on a single-threaded computational model and tried to shoehorn them into an environment whose reality invalidates fundamental assumptions of the model, such as calling a function would execute it once and only once. The harder we've worked to maintain it, the more complex our systems have become. [13]
What would an abstraction across the network boundary look like? A promising place to start would be to assume an environment that can fail as a network does. It seems to me it should have a couple of properties.
- The fundamental assumptions of the abstraction we use shouldn't be invalidated by the eight fallacies, such as functions called means only-once execution.
- The abstraction should allow the programmer to focus on two tasks: initiating the next computation and getting the data ready for the next computation to consume.
- Whatever abstraction works over the network environment should also work in a single-threaded, single-computer environment without needless over-complication.
- Failures need to be taken into account as part of the abstraction. There should be a way for network failures to manifest themselves in the abstraction, so users can handle different cases of failure at a higher level.
Discussion
Web developers are distributed systems engineers in diguise. The myriad of libraries at both the browser/server boundary and the server/database boundary are all searching for the right place to make a boundary in the design space. None of them feel quite right, resulting in both a frustrating user and developer experience.
Is there a unifying pattern or abstraction we can take from distributed systems to simplify the complexity that accrues and accumulates at these boundaries for web applications? What are people trying today to ease the complexities at these boundaries? Do you have insights into what's already been tried, and what might be pitfalls in such an abstraction?
Thanks to Sri Thatipamala, Eric Dementhon, and *David Tran for reading drafts.
Photo by Sirli Jung from Pexels
I think this problem also exists for programs traditionally bound by CPU, such as games and compilers, as even those programs make network calls nowadays. However, I'll mostly speak to web applications as that's what I know well and am concerned with here. ↩︎
I think Paul Chisano put it best about Haskell, a pure functional programming language: "If Haskell is so great, why hasn't it taken over the world? The reason I’ll give is that Haskell’s otherwise excellent composability is destroyed at I/O boundaries, just like every other language." ↩︎
Which if you squint, the Hexagonal Architecture is precise what pure functional languages enforce: a pure core with free monads around the boundaries. ↩︎
As for other popular languages to build web apps in, Python, PHP, Ruby, C#, and Go. They all have some type of support for concurrent programming, but haven't focused on distributed computing. ↩︎
Elixir has been getting some minor traction as a language for web dev, mostly due to the existence of a web framework, rather than its inherent support for distributed computing. I surmise this is because the distributed problems didn't rear their heads until we started adding state to frontends and scaled beyond what a single database could handle. ↩︎
Ever notice how on some web apps, the notification count is still wrong after you've read your messages on different devices? Consistency problems ensue when front-end manages its own state, and it isn't just a pure function of state. ↩︎
There are only a few that actively try to help with client state in relation to the server, such as Recoil Sync and Jotai Async. However, they don't try to build abstractions over a network data fetch. ↩︎
There is currently nascent work on React Suspense, but it's not meant to be a full solution, but rather a way for data fetching libraries to deeply integrate with React to design and orchestrate the different loading states. ↩︎
Phoenix Liveview, Hotwire, React Server Components, Marko, Qwik, and Astro are all different takes on the server-side rendering for rich interactive apps. ↩︎
Or as it's called Vietnam of Computer Science. However, I heard in a recent podcast that DHH would beg to differ, as he believes the ORM did us a solid. ↩︎
This stopping-the-world stems from a single-threaded model of computing. It's a vestige from the early days of computing where we had no choice but to update everything in-place since memory was expensive and scarce. Those days are long gone, but we still think in terms of updating data in-place. ↩︎
But it's not like the people that came before us weren't smart enough. In fact, the people that came up with the Eight Fallacies of Distributed Computing all came from people that worked at Sun. Java is widely used in distributed systems. It just doesn't have as much influence on web applications. ↩︎



