Compiling Composable Reactivity
What if the changes to the input result in state changes that can't be computed fast enough to keep the user interface snappy for an interactive program? Reactivity to the rescue. It's a way to drastically reduce the amount of computation required to compute an output given a change to the input.


The first programs were more like programmable calculators. Fire it up with some inputs and wait for the output. Then in 1963, Ivan Sutherland conceived of a program that facilitated a continuous dialog between computers and humans. You could type or move a pen, and the computer screen updated in real-time. It was the first interactive program.
Though commonplace today, it was non-obvious and took a leap of insight to see it and its potential. But despite approximately half a century of building interactive software, we're still figuring out how to do it well.
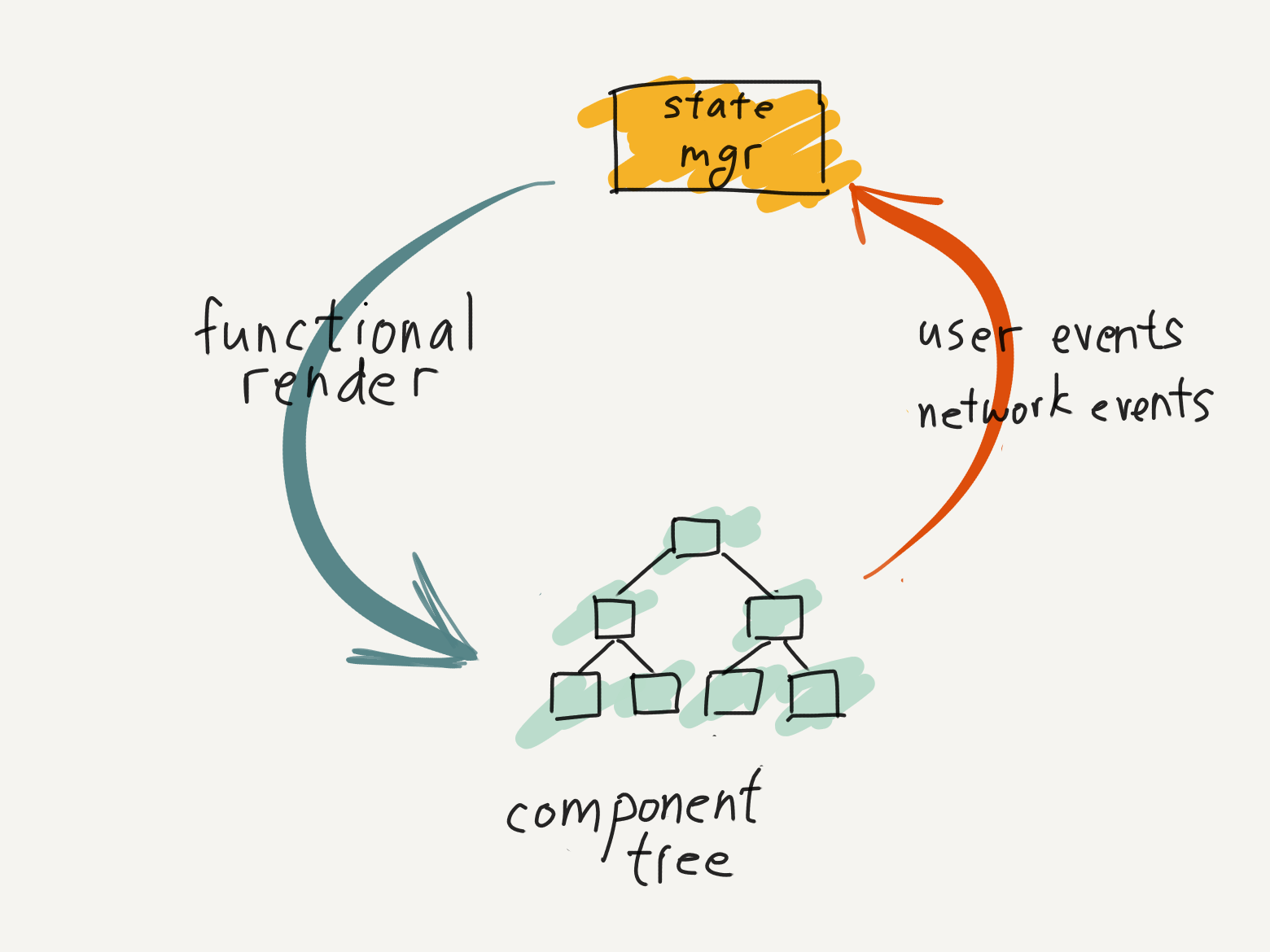
The typical interactive program of today generally has this structure. Starting at the bottom of the interactive loop, a component tree is rendered on-screen. A user clicks on an interactive element, like a button, and generates an event. The event is sent to the state manager to update the application state. Then, the component tree is rendered as a pure function of application state, thus completing the cycle.
In The Broken Half of Interactive Programs, we focused on the stateful interactive side of the main loop (yellow box). In this post, we'll examine the side of the loop where we render components as a pure function of state (green arrow) [0].
What could be simpler? If all complexities of dealing with state are pushed to the stateful side of the main loop, then the functional render side is just dependent on its inputs from the application state. However, there are times when this doesn't hold true. What if the changes to the input result in state changes or view renderings that can't be computed fast enough to keep the user interface snappy for an interactive program? Reactivity to the rescue. It's a way to drastically reduce the amount of computation required to compute an output given a change to the input.
In this post, we'll cover the following:
- Establish why we'd want reactive systems from a user-centric view.
- Attempt to distill and identify the core problem in reactive systems.
- Discuss the tradeoffs for design choices addressing this core problem.
- Speculate on using composable derivatives for reactivity.
What and why of reactivity?
Reactivity is where a program recomputes state changes when its inputs change, at an environmentally determined speed (such as the user's clicks), and not by the program itself. Additionally, reactive systems allow a design where developers specify what the dynamic result should be, without specifying the how thus simplifying the system mental model for programmers. [1]
Why is reactivity a desired property for interactive programs? Interactive programs facilitate a dialog between human users and computers to find solutions to problems the human user is trying to solve. Practically speaking, making computers wait for humans is preferred over making humans wait for computers. The creative flow for problem-solving breaks when humans have to wait. When a program is slow, the human user never knows if the computer is still processing or if it has gotten stuck. It's rarely apparent whether to retry or how much longer to wait. This distraction becomes top of mind, rather than the problem at hand.
In contrast, a responsive interactive program helps the human-computer dialog iterate towards a solution. This dialog becomes a core loop where the user immediately sees the results of making a change. Each result generates ideas of what to try and change next. The quicker the cycle, the faster a user can iterate through a problem space in search of a creative solution. [2]
Games call this loop a core game loop, but we can simply call it a core loop. The time budget available to return a computed result is defined by how fast a human can cycle through the core loop (remember, we want computers to wait on humans). The faster the cycle, the shorter the time budget.
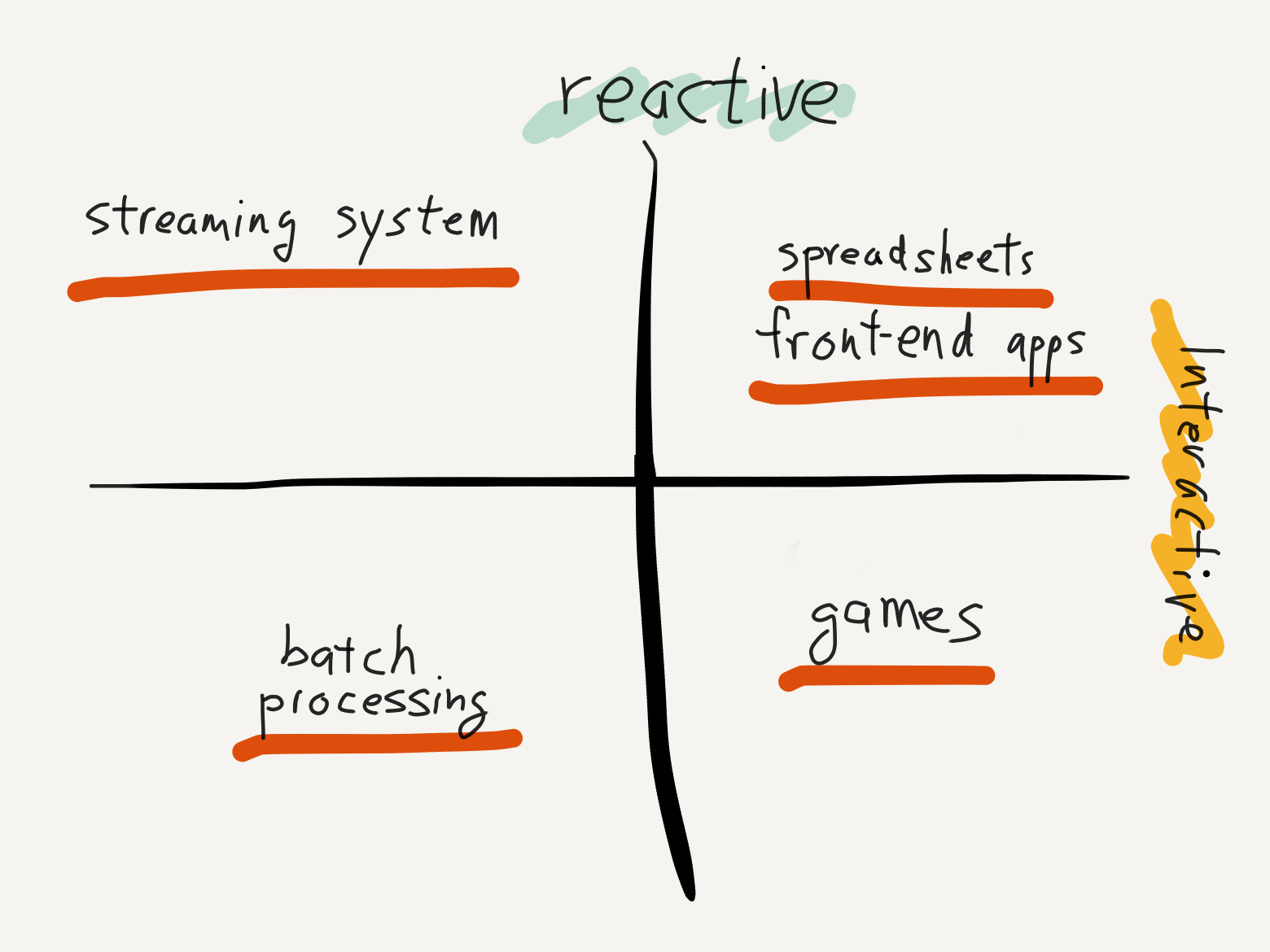
And yet, not all interactive programs require the use of reactive techniques. Games are the best example of interactive programs that rarely use reactive techniques. Why is this? A game's goal is to be fun, and fun derives from allowing the player to make meaningful choices in the simulated world. An exact accurate simulation of the world is often secondary (and sometimes in opposition) to the fun. Hence, a game can oftentimes get away with approximate answers, so they opt to use the simplest and fastest computation, not the most accurate one. This gives them much leeway to be fast without reactive techniques. [3] That said, there is recent work on reactive 3D scene rendering for the web.
However, there are still good reasons to use reactive techniques for both interactive and non-interactive programs. One reason is in domains that require exactly the right answer without redoing all the work. For non-interactive programs, good examples would be build systems and borrow-checkers. For interactive programs, the poster child is the venerable spreadsheet.
Another good reason to leverage reactivity is when the size of the dataset is too large to conceivably return a computational result in milliseconds through brute force. Even with fast computers, there are computational jobs that are beyond the reach of brute force to return a result within milliseconds. For example, streaming systems for big data often need to process petabytes of data. These systems leverage reactivity to make processing practical and tractable.
Lastly, a good reason to use reactivity is when a required external subsystem is too slow. For example, Front-end web apps render using browser DOM elements, which are well-known to be heavyweight objects that are expensive to create and destroy.
But then, why not just write imperative code to just minimally update the DOM? This can work, if the scope of the state changes required by the application is small enough. For example, if there's just a single list of elements to update, such as in a todo list or pins on a map. But just as manual memory management is manageable by a human up to a certain point, so it is with manually updating the DOM. A more complex UI with inter-relate parts, such as a vector drawing app is likely to tax a developer on what state changes should update which part of the view and when. At least in front-end web apps and Rust GUI ecosystems, we've found declarative one-way data flow modeling of GUIs to be an easier mental model of the system for developers.
A declarative interface, by definition, removes control from the developer so they only have to specify the what, not the how–the exact series of steps. This responsibility of the how doesn't go away. It's merely shifted from the developer to the reactive library. But now, efficiency is also the responsibility of the library. Reactivity allows front-end web frameworks to support a declarative interface while ceding control to the library to maintain efficiency by minimizing changes to the slow DOM tree.
In short, reactivity is a complexity that system implementers are willing to deal with in order to make the core loop practical when brute-forcing an exact answer isn't. [4]
The core problem
The design space for reactive systems is large, and different people have covered different sets of considerations subject to different constraints. At the end of this post, there is an overview of various posts on the design space for various reactive systems.
To summarize the various attempts to parameterize the design space of reactive systems, we ask: What is the core problem when designing such a system?
The fastest program is a program that does nothing at all.
- Programming Koan
To make a fast program, just never make it slow.
- Paul Buchheit
Fast programs are largely about exploiting the inherent data structure of a problem domain to avoid doing work. This can involve not doing work that you've already done, or not doing work that doesn't affect the final output. Grep is famously fast because it does so little.
Reactive systems model computation carefully to answer the question: If the input changes by this small amount, what's the minimum re-computation to get the same answer as the full computation?
To answer this question, creators of reactive systems need fine-grained control over the execution of code to decide which computations to recompute. We achieve this with two techniques commonly used together.
First, we ask the developer to rewrite their code more explicitly as a computational graph of data dependencies. In Apache Spark, it's a program with only the functional operators it makes available. In React, it's the react hooks with data dependencies relating them to one another. In build systems like Make, it's explicit file dependencies between build steps.
Second, the reactive system implements a scheduler to decide which computation should be executed and when. This is often embedded in the reactive library. For languages that don't allow runtime modification, such as javascript, the scheduler is implemented in userland. In fact, React is actually a runtime on top of a browser. [5]
Now then, should the system propagate deltas or should it perform diffs between the subsequent computational graphs?
Propagating deltas means that each node computes how a change in input will change its output. This change in output, rather than the output value itself, is propagated through the computational graph.
On the other hand, performing diffs means that we build an entire new graph on every cycle through the core loop. And then we diff the current vs previous computational graph to see what has changed.
In An Opinionated Map of Incremental and Streaming Systems, the difference between the two approaches is called unstructured vs structured systems.
Structured systems typically propagate deltas through the computational graph, but the downside is that they restrict the operations available to the user. Unstructured systems allow for any type of user operation, so it typically executes diffs. The downside is the implementation complexity, and if the update semantics aren't internally consistent, it is frustrating to debug.
This is a base design decision that affects everything else since that is the core problem: it's the mechanism by which we determine whether or not to recompute. Let's compare the trade-offs between the two designs.
The limits of a structured system
Structured systems restrict the set of operators available to the user. But with this carefully picked set of functional operations, deltas can be propagated through the entire computational graph. Streaming frameworks seem to favor this design. For example, Differential Dataflow propagates deltas along with multi-dimensional counters to label intermediate computational results at different points in time and in loops, so it knows how to combine them correctly when all of the input data for an output data has been seen.
Because we know what has changed, rather than just that something has changed, we don't need to perform tree diffs or define equivalence. All the problems in unstructured systems mentioned above are answered by the delta.
Why not default to propagating deltas in all reactive systems?
It seems to be partially a cultural stumbling block. Structured systems would require mainstream developers to rewrite their algorithms in this limited set of functional operators. Given the limited (but growing!) popularity of functional programming, it's a tall ask. Big-data streaming systems have orders-of-magnitude bigger workloads than front-end web frameworks, so the choice of delta propagation over tree diffs is likely because of performance. If a limited operator set is the trade-off for performance and tractability of large problems, users of streaming systems are more than willing to make that trade.
That said, even if this trade-off was made willingly, it can be hard to use. MapReduce is famously hard to translate into queries by hand, and even functional systems like Apache Spark provide more operators than just map and reduce now for jobs that query. It now has a SQL variant on top of the functional language for this very use case.
The baggage with unstructured systems
In unstructured systems, we can allow arbitrary computation, but because unstructured systems don't propagate deltas, it has to take the diff between the previous application state/tree and the current application state/tree in the computational cycle. It has to have an answer to the equivalence question: "what does it mean when two things are the same?", so it can make decisions about whether or not to recompute and in what order.
Why would that be difficult? Equivalence is already a subject of debate amongst mathematicians, not to mention amongst programmers. Some software systems treat things with the same memory location as equivalent. Other systems treat pure functional computational nodes with the same inputs as equivalent.
These attempted one-size-fits-all answers are problematic. They're insensitive to the problem domain's inherent data structure that yields exploits for faster execution. One class of these exploits is to skip recompute when changes to input don't change the output in a meaningful way. For example, if the problem domain is compiling code, changing a comment shouldn't trigger a re-compilation. Hence, many of these unstructured systems have a default consistent and predictable (if dumb) recomputation heuristic but leave an escape hatch ajar for the user to override for their specific domain.
But leaving it up to the user to wire up case-by-case is a recipe for bugs and glitches, and it's easy for a user to get it wrong and end up with a hard-to-debug system. If a computational node decides to re-run more often than needed, then it is over-subscribed. (correct but not efficient) If a computational node decides to re-run less often than needed, then is it under-subscribed. (minimal computation–but at worst incorrect answers, at best just glitchy intermediate answers that are hard to debug) As The Incremental Machine and An In-depth Explanation of MobX both noted, this is a cache invalidation problem in disguise.
How come it's a hard problem to know when the data changes in unstructured systems? We know exactly when the data changes--it's when the dirty bit gets set. The reason we set a dirty bit is that triggering recomputes at this moment would result in updating all the children to intermediate values. This means that those children might be processed again as we traverse down the computation graph. Until all nodes have been marked, the process doesn't have enough information to ascertain the minimal set of computational nodes to run for the correct output. The decision of whether or not to invalidate cannot be done locally, one step at a time in a single pass.
Other complications
So far, we've mostly considered this problem of designing reactive systems as deciding whether or not to recompute specific nodes of a computational graph. The other knobs for tweaking the design of reactive systems have to do with how they would work with other commonly used language features.
Some of these systems don't allow for loops and functions. It is true you might not need a loop to iterate across datasets if you have a map operator, but what if you need loops to iterate across time and across a core loop cycle? Sometimes it would be needed to iterate a dataset to a fixed point. How would reactive systems model functions? Is it possible to reuse parts of the computation graph, or even pass it around to insert dynamically? Self-adjusting computations explicitly address this use case.
The problem of reactivity is complicated when a computational node in our graph has a data dependency that lives outside of our system across the network. How closely the application is expected to sync with remote data? Does the node wait forever for data? How often should it check? What happens on error, and should the user know? Most of these questions can't be answered by the reactive system and are left to the user to manually hook up. As a result, it's often error-prone and feels glitchy to the end-user without a concerted effort and attention paid by the developer. [6] This is a problem most acutely felt by front-end frameworks, since streaming systems typically have a reliable data store to draw from.
That's not all. A reactive system's design is further complicated if the system is expected to handle old data. Since some of these formulations of reactive systems keep internal state–such as when a fold is supported as an operator–complications arise when parallel or concurrent computation is introduced, such as data races. That's where front-end frameworks fall over, as they're not built to address these problems, and people reach for streaming systems built for big data with all their constraints.
These complications are mentioned for completeness, rather than as an attempt to address them. The decision of whether and how much to recompute is at the heart of the problem, and the two approaches between structured and unstructured are limited in their perspective ways. Is there a way we can have the best of both worlds?
Does Discrete Differentiation exist?
In this search through the current state of reactive systems, one question loomed in my mind. As opposed to the common numeric differentiation, does discrete differentiation exist? For example, how would we compute, represent, and compute the derivative of a functional operation such as string append? More importantly, is there a Chain Rule for almost any functional computation?
In numeric computations, if we want to compute
f(xt) where xt = xt-1 + Δ
(current input is the previous input with a little change), we can take one of two routes. We can either compute it directly or we can compute
f(xt-1) + f'(Δ)
In reactive systems, we'd prefer the latter if f(xt) is expensive to compute, but f'(Δ) (the derivative) isn't.
Just finding the derivative of a specific function isn't enough. To remove the constraint of limited operators, we want a Chain Rule to help us compose the derivatives. The Chain Rule would compute the compositional delta from end-to-end. That means we wouldn't need to calculate diffs between trees, mark dirty bits, or worry about equivalence problems when comparing two trees. It would also be internally consistent as inputs changed.
What are some open questions?
In addition, not all operators have a delta to propagate. Cryptographic functions like SHA256 are, by design, incrementation proof. The whole point of their design is to generate outputs that are statistically white-noise when their input changes a little bit. But even if most functional operators had a delta, it's not yet clear to me what it would look like for classic operators like append, concat, push, pop, etc.
And as often noted in introductions to auto-differentiation for deep learning, symbolic differentiation for numeric computations often becomes untenable because of the combinatorial explosion of terms as you take the nth derivative. The deeper the neural network, the higher the derivative. Worse, the terms from one function are often repeated and entangled in different parts of the entire expression–a result of a composition that doesn't compose cleanly.
What would a possible solution look like? The closest thing I've come across is Conal Elliott's Compiling to Categories. [7]
Compiling to Categories
The idea is to compile a program into a category theory representation, called Closed Cartesian Category (CCC), as an intermediate representation (IR) of code. We can then use a "template" to compile this IR into anything else. In our case, we want to compile into functions that propagate deltas but also still compose.
In Conal Elliott's demos, he compiles a short program into CCC. And then, using a "template", he can compile it into a graphical DAG representation.
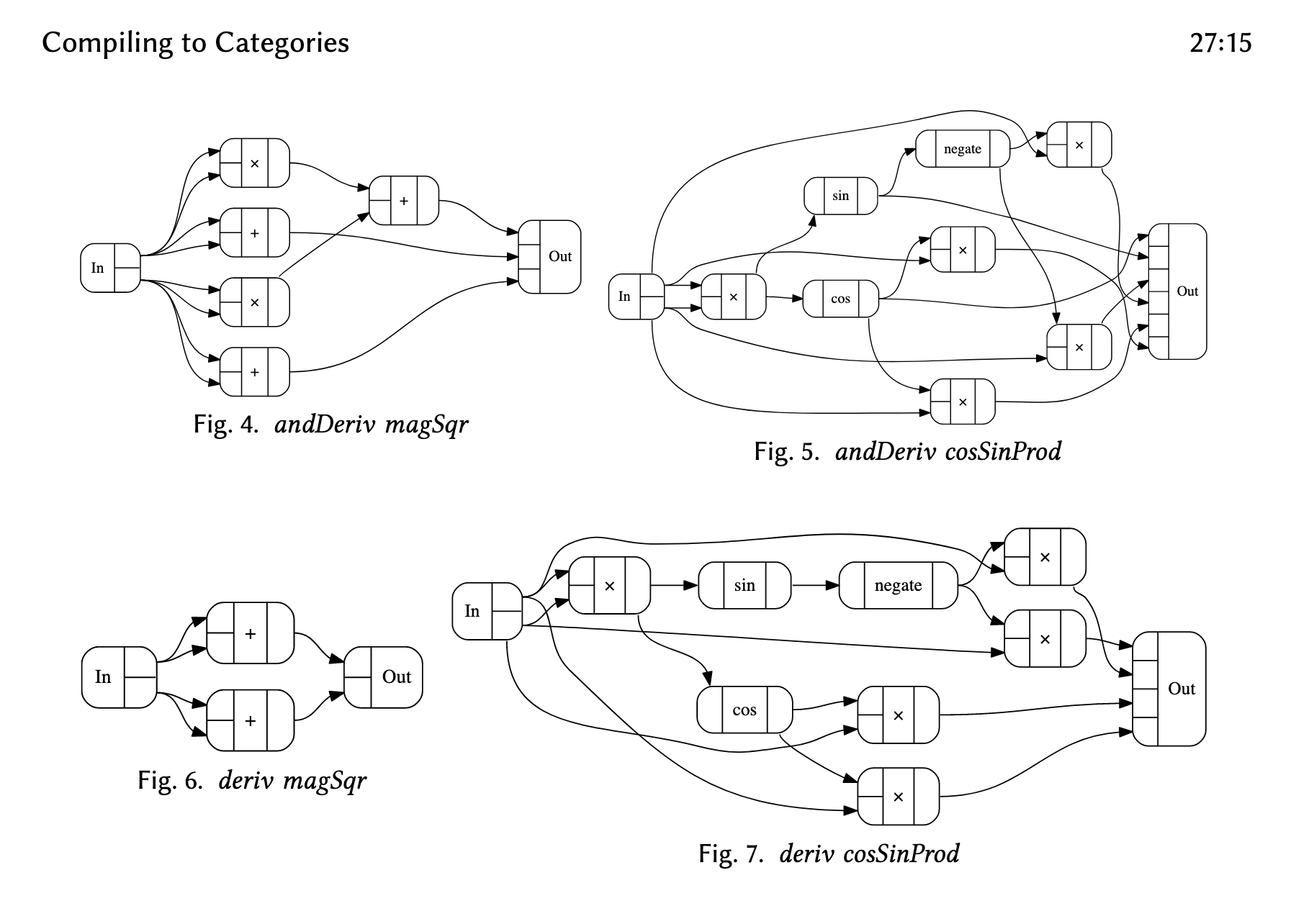
Then, with the flick of a different template, he's able to compile the same code into Verilog, a language for programming FPGAs. With another, he's able to compile it into GLSL for a GPU.
But the real magic happens when we compile the IR into code with functions that are function-like but aren't traditional functions–they're embellished in some way.
One such example is functions that keep track of their deltas–differentiable functions. Differentiable functions are useful for constructing neural networks with auto-differentiation since manually writing derivatives for each layer is error-prone and hard to debug. With a template, he's able to compile a program to be auto-differentiable.
Auto-differentiation isn't a far stretch from incremental and reactive systems. And indeed, he has a section where he addresses incremental systems. [8] The purported advantage of this construction of a reactive system is that differentiable functions compose cleanly, and it doesn't hold state, hence making it easily parallelizable.
Discussion
While reactivity is deceptively simple when pure functions are involved, it's easily complicated by temporal locality, the choice of propagating differences, and how equivalence is determined. All of this complexity is absorbed by the implementor in hopes of providing a logical model for the end user that is functional (or declarative), and will run fast enough to produce a result in the short time allotted by the user's core loop cycle speed.
It's intriguing whether this construction of compiling to and from Closed Cartesian Categories can yield a process by which reactive systems are much simpler to build and maintain. Even better if it yields faster systems with more flexibility in operations.
Could reactive systems be more broadly used to build databases and query languages? The answer seems to be yes. Differential Datalog and SkipDB are two attempts in this direction. Could we build a runtime that is reactive by default? Could we provide a better developer experience with a reactive compiler? Or will it just collapse on itself with complexity and be hard to use/debug due to inconsistencies?
Through all this, it may not be worth doing any of it at all, depending on the domain. Today's computers are faster at doing math, than it is at loading data from memory. Memoization may be slower than just redoing the computation all over again. It'd really have to be an order of magnitude slower than loading from main memory for these techniques to be worth it.
That said, it's clear to me that the current technique of diffing states in unstructured systems has lots of problems, and that propagating deltas with composable constructions seems like a more promising way to go.
Many thanks to Eric Dementhon and Sri Thatipamala for reading drafts.
Supplemental overview of the design space for reactive systems
Towards a unified theory of reactive UI focuses on reactive systems for building GUIs in Rust. The primary mental model is simplifying GUI rendering as a pipeline of steps transforming application state through intermediate representations to become a set of draw calls to the GPU. The design decisions for such a system are:
- data structure vs a computational trace. The representations of various states after transformations can either be a tree data structure or an execution trace (a linear order of instructions).
- push vs pull interface. Is code recomputed through a function call (pull), or are changes notified to those subscribing to those changes (pull)?
- explicit deltas vs diffing. To implement a declarative UI and to provide incremental computation, we'd need to discern what has changed. Should we propagate deltas from cycle to cycle in the core loop? Or should we diff the current and previous trees representing state in the pipeline?
- identity by: object reference vs key path vs unique id. Lastly, given a changing state tree from cycle to cycle, how do we get a stable identity for nodes requiring change?
Build Systems a la Carte focuses more on build systems. While different on the surface, it's effectively the same problem that GUIs try to tackle. A build system must be a) correct and b) rebuild out-of-date keys at most once. By correct, it means when the build system completes, the target key and all its dependencies should be up-to-date. And build order of the out-of-date keys should respect their dependencies. Hence, it focuses on two key design parameters that are orthogonal:
- What order to build. This decision ensures the dependencies of a computational node are computed before the node itself is computed.
- Whether to build. This decision ensures nodes aren't computed more than needed.
An Opinionated Map of Incremental and Streaming Systems, on the other hand, breaks down the variety of reactive systems into a decision tree.
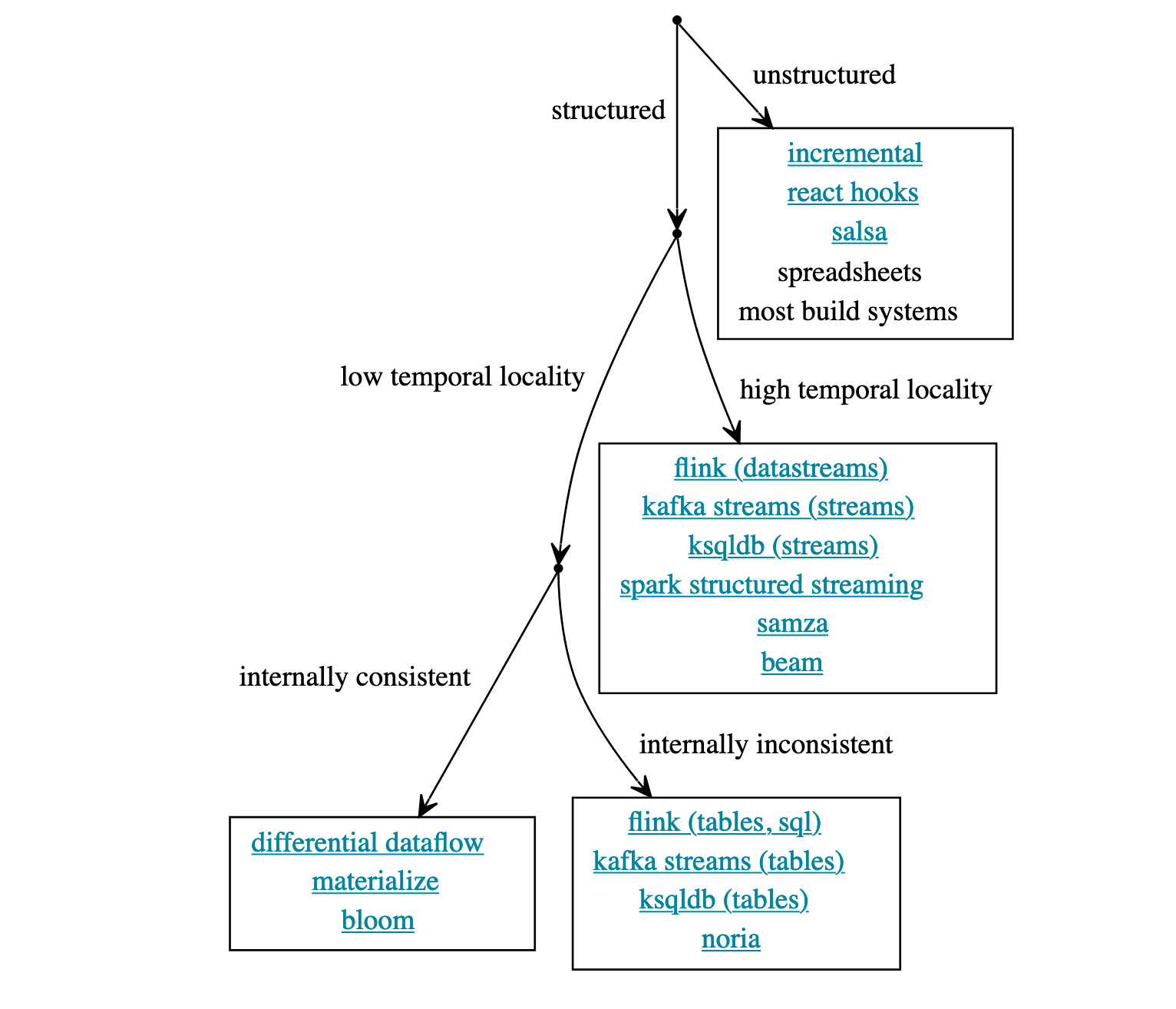
- Structured vs Unstructured. Structured systems restrict the operations available to the user, and they typically propagate deltas through the computational graph. Unstructured systems allow for any type of user operation, and typically execute diffs between the current and previous computational graph to determine which nodes require recomputation. (similar to explicit deltas vs diffing mentioned above)
- Low Temporal Locality vs High Temporal Locality. For streaming systems, data can arrive out of order. How do we incrementally update the result when old data arrives (low temporal locality)? Or do we have a tight window where we ignore old data (high temporal locality)?
- Internally Consistent vs Internally Inconsistent. When systems are incremental, the internal state will vacillate as values stream into the system. The systems that aren't internally consistent could be in a state that doesn't make sense when read. This can be a problem. In GUIs, this manifests itself as visual jank when a page is loading.
- Eager vs Lazy. An eager system actively computes new outputs whenever the inputs change. A lazy system waits until the output is requested. Lazy systems, however, can't be used for monitoring use cases.
Breaking down FRP focuses more on reactive systems for web apps. It identifies the variety of properties you'd want from a functional reactive system, but notes you can't have them all in the same system. They are trade-offs that you'd have to pick and choose. The following properties are
- History-sensitivity. How do we redo our computation incrementally when old data shows up in our front-end? (similar to temporal locality above)
- Efficiency. This refers to both space efficiency and computational efficiency. Minimize both the amount of past to remember, and minimize the amount of recomputation on an input change. However, it's hard to have both.
- Dynamism. This is the ability to reconfigure the computational graph over time, as a response to changing input. But a dynamically changing graph makes it harder to determine what it should do when old data shows up.
- Ease of Reasoning. Clean semantics that makes it easy to reason about the behavior of the system. (This is related to internally consistent vs internally inconsistent above)
[0] A survey of unidirectional front-end architectures shows us some variations.
When people say UI is a pure function of state, the state they're referring to is application data, not the state of various widgets. While you can consider widget states as part of the application state, it's too fine-grained. The end user rarely cares about the state of a widget.
[1] Some choice quotes on a definition of a reactive system.
The essence of functional reactive programming is to specify the dynamic behavior of a value completely at the time of declaration
https://svelte.dev/blog/svelte-3-rethinking-reactivity
Reactive programs maintain a continuous interaction with their environment, at a speed which is determined by the environment, not by the program itself.
Gérard Berry (RR-1065, INRIA. 189)
[2] In Inventing on Principle, Bret Victor puts it in a different way.
...here's something I've come to believe: Creators need an immediate connection to what they're creating.
And what I mean by that, is when you're making something, if you make a change or you make a decision, you need to see the effects of that immediately. There can't be a delay, and there can't be anything hidden.
In fact, most consumer-facing applications are of this nature: playing games, writing emails, constructing 3D models, and more.
[3] There are other reasons games are fast, such as using languages that allow for SIMD. That said, the data pipe to the GPU is slow, so games tend to batch up all the triangles it wants to draw and push them out to the GPU all at once.
[4] I'm referring to the complexity we're willing to deal with as implementers, not as client-user developers.
[5] It seems both Haskell and Julia allow a programmer to change the runtime. Wouldn't be surprised if both Lisp and Smalltalk allow this as well.
React is a runtime because it actually has a scheduler that decides when and how much to run the hooks and rendering. It will yield to the browser when its time is up, and resume where it left off when it regains control from the browser.
Not all front-end frameworks are runtimes. Svelte, takes a different approach. It compiles reactive code into imperative code. It is the imperative code that is run in the browser.
[6] Immutability and passing of values help here. If interested, Hyperfiddle and Datomic offer a refreshing look at the problem here.
[7] Conal Elliott is the originator of Functional Reactive Programming, which influenced Elm, which in turn influenced Redux. But since then, he's moved on to this idea of compiling to categories.
[8] Incremental Computation is discussed in section 7.6



