When declarative systems break


A couple of months ago, I had to reload everything I knew about reactivity back into my head. I discovered that I missed a large corner of the development around unstructured reactivity, by way of Signals. From arguments about signals vs. functional components on Twitter and in post comments, it sounds like the issue concerns developer affordances of different APIs. From the marketing of signal-based frameworks, it sounds like the issue is a matter of performance.
But the reasons why you'd choose signals over functional component-based frameworks like React have more to do with two things: the shape mismatch between the application data and the UI view and whether the performance requirements can tolerate the mismatch.
For most web apps with median performance requirements, functional component-based frameworks like React work really well, especially when your application state closely matches your UI structure. The declarative API makes maintenance and the mental model easier than it would be otherwise.
However, if the gap between the shape of application state and shape of UI views grows, React’s declarative execution model can lead to inefficient updates, hurting performance. Without built-in escape hatches, developers facing these mismatches turn to Signals—trading some of React’s declarative reasoning for more precise and performant state updates.
The Unspoken Assumption
What happens when a piece of application state needs to be rendered by two sibling UI components? React's common advice is to pull that state up to the closest common ancestor and pass that state down as props to the children.
The fundamental assumption of React is that the shape of your state dependency graph is similar to your component tree. If that's the case, then the affordances of React and the granularity of reactivity are in alignment. That might hold for many apps, but when it doesn’t, you end up forcing your component hierarchy to revolve around these shared state.
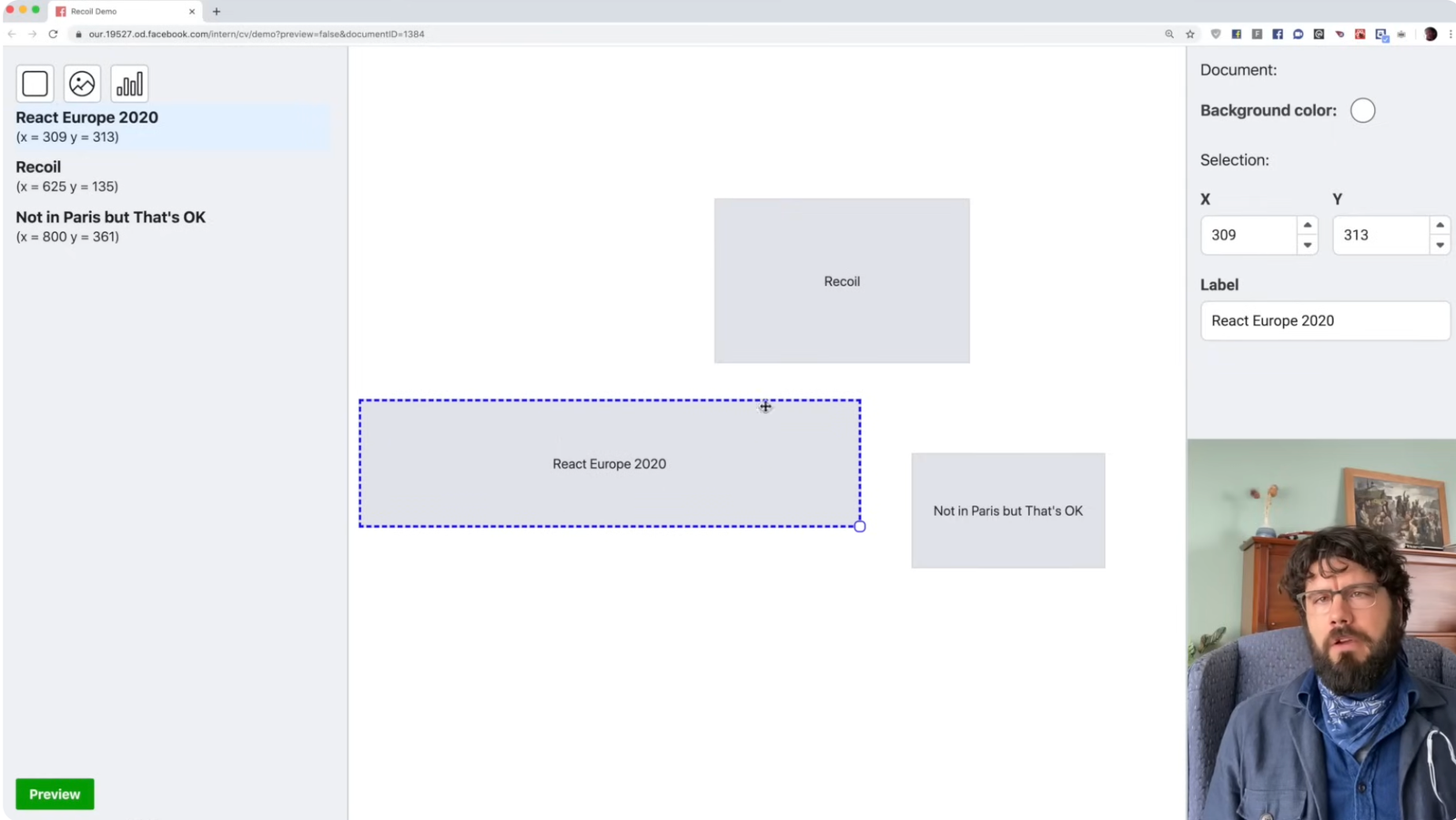
Imagine a canvas application with sidebars, toolbars, and overlays. An object in this common visual-editing app needs to be represented in both left and right sidebars and the middle canvas. The object is rendered visually on the canvas, as a part of an object hierarchy on the left sidebar, and with its properties on the right sidebar. Each region of the UI might need to observe and mutate the same piece of data, but they all live in different parts of the component tree. Following React’s recommendation, you keep lifting state until everything that needs to access it can do so.
Unfortunately, that may mean large swaths of the UI re-render every time the state changes. If your components are mostly functional, that might not be so bad, but if they contain effects (useEffect) or memoization (useMemo), every change can trigger a wave of potential re-computations and callback closures. It’s error-prone and easy to lose track of dependencies. React also opts for correctness over performance by default, so it'll default to re-rendering. Makes sense as a design goal, if one considers how confusing it is when an incremental system updates halfway, and functions are considered cheap to run. However, this can also be a source of frustration when the app seems to keep slowing down and you have to keep providing hints to the runtime via dependency lists and various hooks to not over-render. It can be hard to discern why multiple renders occur without profiling tools. In practice, if the users are performance sensitive, it can feel like you're spending all your time on the submerged mechanics of hinting the declarative runtime instead of touching the viewable components delivering value to users.
Part of the issue is the double-edge of declarative APIs. They're great for reducing complexity in the average case, because the developer only needs to declare the intended goal state. There is nothing else. The system figures out how to find and traverse the path from the current state to the goal state. This frees the developer from keeping track of the previous state in order to compute the next state, and managing state is often the source of bugs.
Unfortunately, every declarative system embeds assumptions about how to traverse the state space during computation from the current state to the goal state. When those assumptions fail, performance suffers because the chosen path from the current state to the goal state is inefficient. Most declarative systems offer no escape hatch or way to influence the execution policy. At least SQL provides EXPLAIN so you can see its plan—many others don’t even offer that. As a result, when performance is critical and these assumptions break, developers often have no choice but to abandon the system entirely and build a new solution from scratch.
Signals is one dominant alternative. It lets you define a separate dependency graph that tracks how state updates should flow, independent of the UI view tree. Whenever a signal changes, only the specific parts of your interface that depend on it need to re-render. This can lead to substantial performance improvements in applications that have complex or cross-cutting state.
The trade-off is that freely accessible signals can get messy if every component in the UI view tree can update them. That’s why library authors often offer namespacing or scoping for signals, so you can define how far their influence extends without losing track of where updates come from. In addition, it leaves behind all the affordances of a declarative API, where the developer only has to declare the intended goal. Hence, developers might need extra help reasoning about state updates, such as a visual debugger for the state dependency computational graph.
For developers weighing their options, the trade-off is pretty clear: stick with React if your data aligns well with your UI and you value a straightforward, mature ecosystem. But if you repeatedly find your data graph crossing multiple parts of the UI, or you need to avoid re-renders at all costs, Signals could be your best bet. This can be hard to tell a priori, as both can evolve over time as the understanding of the domain changes and hence the requirements change. In the end, it's trade-offs.
Declarative escape hatches
This question transcends React and Signals. This trade-off plays itself out across the programming landscape: retained mode vs immediate mode, functional vs object-oriented, and in declarative vs imperative configuration management. Even in the world of database queries, where SQL wins by a large margin, there are still skirmishes with imperative alternatives like PL/SQL and Transact-SQL. In almost all cases, the desire for reduced complexity in managing state draws developers towards declarative systems, and the desire for performance pulls them away. Can a declarative system—one that focuses on describing the end state rather than step-by-step updates—be extended to handle edge cases requiring more granular performance?
Improving execution internals
One angle of attack is to keep the declarative API as is, and just improve a declarative system's ability to judge which computational branch to go down to get to the goal state. The current ability of React to judge what branch to examine is hampered by the limitations of Javascript in this regard.
- Dynamic Types and References: JS arrays and objects are reference-based, lacking an efficient built-in mechanism for detecting which nested properties have changed. Structural equality checks grow expensive and quickly become impractical for large data.
- Immutable-by-Convention: React and similar frameworks rely on immutability so they can compare references for performance. Yet even with disciplined immutability, the system can’t know exactly which pieces of your state changed unless you manually break them into discrete atoms or rely on advanced libraries.
- Component Granularity: React treats a function or class as the smallest unit of re-render. Fine-grained updates would require skipping parts of a single function’s output—something that clashes with the idea of purely atomic render functions.
Let's try tackling each of these in turn.
What if we had true immutable complex values? A truly immutable language or runtime, like Clojure or Haskell, can efficiently detect changes via structural sharing. It knows exactly when something has changed, and can avoid computational branches it knows for sure hasn't changed. The system wouldn't need heuristics to guess or require hints from the developer. The downside is that immutable values are grow-only, and most languages don't support their semantics by default. Hence, there would have to be some kind of expiration policy for the history of changes in an immutable value.
Perhaps instead, we can use version clocks to indicate change internally? Imagine attaching a version clock to each field or sub-object. When that field changes, its clock increments. This allows a more direct mapping of ‘property changed → which UI depends on it.’ In essence, it introduces partial reactivity: your runtime or compiler can skip re-renders for unaffected properties. On the plus side, this structure isn't ever-growing, like immutable data structures. And if everything is truly pure and transparent, you won’t get the wrong computations—at least in theory. But real apps often have side effects, dynamic property usage, concurrency concerns, or incomplete signals about exactly which bits of code are dependent on which state. That’s how “wrong” decisions or extra re-renders slip in, even in a system with perfectly immutable data or carefully maintained version vectors.
Even if branch prediction is solved with immutable values or version vectors that something changed, if your declarative system is still re-running entire ‘components’ or top-level functions, then you only solve half the problem. You know something changed, but you still lack a built-in way to skip re-rendering subparts of the UI unless you subdivide your data into separate states, each pinned to a unique piece of UI.
What about using algebraic effects for finer granularity than a single functional component? Algebraic effects could theoretically let you intercept specific sub-expressions within a single rendering function. Each sub-expression might read from a piece of state and produce an effect, so if that piece of state doesn’t change, the runtime can skip re-running that sub-expression. Hence, any state changes within a component are yielding effects that alter a UI View. I think if you squint a little, this is along the lines of what Signal-based frameworks do.
Lastly, there are algebraic incremental approaches like differential dataflow and DBSP that restrict operations for moving state to those that can be defined incrementally; for any previous input x, if I change the input to x + 𝚫, we can compute f(x + 𝚫) without recomputing f(x) all over again. This approach seems very promising, but I suspect there is a different kind of alignment problem here. Just like in CRDTs, while the merge might be algebraically correct, you might get semantically nonsense merges. I suspect it might be the same for these algebraic incremental approaches.
Giving declarative policy hints
Perhaps any domain will have edge cases that need to be nudged by the developer. But instead of diving into the minutiae of when to re-render each sub-expression imperatively as an escape-hatch, one could imagine a higher-level, purely declarative policy system. In this approach, you’d define explicit relationships among various state slices and UI views. For instance, you might declare, “These three states are tightly coupled and should always update together,” or “This component’s render only depends on fields A, B, and C from the global state.”
The runtime could then use those policies to group updates intelligently, determining which components can or should re-render at the same time. This is less about micromanaging the exact lines of code to skip and more about giving the framework a bird’s-eye view of which parts of the data graph belong together.
In principle, this moves some complexity from low-level reactivity (like signals) into a set of higher-level declarations—an attempt to keep the developer experience more ‘big picture’ rather than diving into partial reactivity on a field-by-field basis. But implementing such a policy system is still far from trivial.
One major challenge is the need for a purely declarative way to define how state partitions map to UI partitions, so the runtime or compiler can interpret those policy statements and assemble an efficient dependency graph. Even then, developers typically end up labeling or grouping their data—a practice that feels a lot like signals, just at a coarser level—revealing how much low-level reactivity logic still lurks behind the declarative veneer.
It’s an intriguing middle ground. By defining relationships—rather than line-by-line checks—you’re nudging the system to do partial updates without stepping fully into an imperative approach. Yet, you still risk complexity if policies become too fragmented or if states have inter-dependencies that defy simple grouping. Ultimately, it remains an open question whether any such policy system could achieve the fine-grained performance benefits of Signals without reintroducing a fair amount of ‘reactivity bookkeeping’ behind the scenes.
The Tension in Declarative Systems
Ultimately, any purely declarative system is predicated on the idea that you describe what you want, and the framework figures out how to accomplish it. Once you start dictating precisely which parts of the system can skip reprocessing—and under what conditions—you’re veering into partial reactivity. You’re effectively telling the system how it should schedule updates, imposing custom rules on the execution plan.
Of course, you can graft fine-grained controls onto a declarative model, but each addition gradually erodes its simplicity. You might need to annotate or restructure code so the runtime can pinpoint which sub-expressions rely on specific pieces of data, while the framework itself maintains a specialized “update graph”—much like Signals. Inevitably, you’ve stepped away from a purely declarative approach into a hybrid that merges declarative goals with partial reactivity under the hood.
You can approach this issue asymptotically, but there’s no free lunch: staying fully declarative often means accepting broad recomputations that go beyond what’s strictly necessary, while trying to micro-optimize every expression leads you into describing how sub-expressions should update—edging into partial reactivity. Put differently, the deeper you dive into fine-grained updates, the less you can rely on a purely declarative “describe the goal” style, because you inevitably end up declaring which pieces of your code need to update and when, rather than just what the final state should be.
In other words, the more the system needs to handle fine-grained updates, the less purely declarative it becomes. You can blend paradigms, but that hybrid approach often demands more mental overhead and/or compile-time machinery.
End of the day
So, is it impossible for a declarative system to handle all edge cases with top-tier performance? Not strictly. You can embed partial reactivity or Signals-like mechanisms via deep immutability, version clocks, algebraic effects, or advanced compile steps. But each move in that direction redefines the purity of your declarative abstraction and ushers in added complexity.
If your data shape aligns with your UI and you don’t need hyper-optimized updates, a declarative framework remains a wonderful solution. But for edge cases—like real-time apps with interwoven data dependencies—other paradigms do a better job of pinpointing precisely what changed and when. After all, it’s hard to remain ‘purely declarative’ once you start asking the system to skip internal steps under certain conditions.
That’s the central tension: declarative frameworks elegantly solve the common case but inevitably bump into scenarios that push them beyond their comfort zone. There’s no perfect solution that’s both purely declarative and infinitely adaptable. As soon as you need the latter, you’re knocking on the door of an imperative stance on updates.



