The Hidden Scaffolding Behind Production Vibe Coding


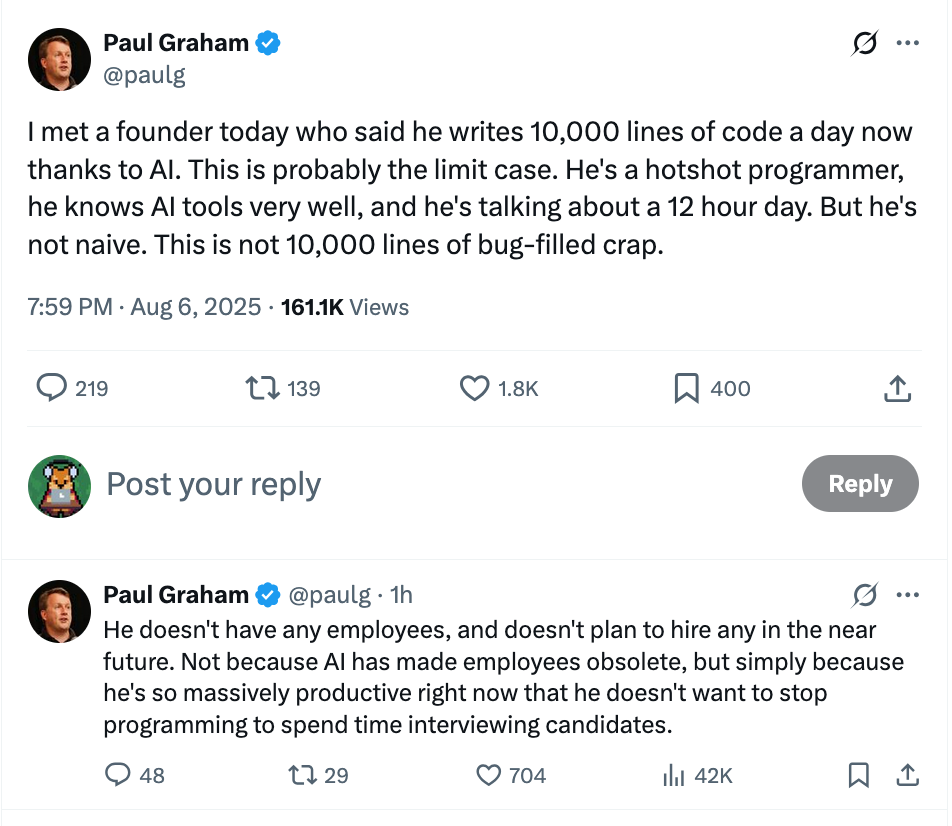
I’m not near a level where it’s 10k LOC per day, but the volume of commits is noticeably higher w/ Claude/Codex now. Back in Feb/Mar when Claude Code came out, I was writing an implementation of DBSP (incremental computation with some mathy stuff) and I couldn’t get Claude Code to work for me. The code would often not be structured well for a long term requirement, or it was just subtly wrong in a way I’d discover later. I thought maybe it was just my domain, since it wasn’t a web app—so maybe not enough training data. Turns out I was just holding it wrong.
What didn’t work:
- Thinking that the first draft of describing what I wanted and that’d be enough detail. There’s often stuff that’s missing.
- Trying to review every change as it was happening. If you’re going to vibe code, you have to let go and just ride the wave.
- Working at the granularity of tasks I’d give myself. It needs to be broken down into intern-sized tasks.
- Keep hammering away at getting it to rewrite if the code isn’t working.
There are two modes to vibe coding. First is for ephemeral apps, where you one shot a small tool (might even be throwaway) that you would have written yourself, but the cost wasn’t worth the squeeze. This can be very helpful if you get in the habit of noticing that itch. Second is for production engineering work, and this is what people after. From the way people talk about it, I didn’t realize it takes a lot of scaffolding for it to work.
A good mental model for me on LLM responses is that it’s a midwit median response if I have no real taste for nuance on the topic. But if I do, like in engineering, I have to make explicit much of the tacit knowledge in my head as scaffolding. Agents need a lot of guardrails in place to generate acceptable code that matches your taste and your organizations tastes.
What are the scaffolding?
First, the typical stuff espoused by engineering culture:
- work in a language that uses type checking and don’t allow
anysprinkled liberally in your code base like confetti on Mardi Gras. - if you have a build process, make it easy to invoke from end to end.
- fast unit tests. 80% coverage.
Claude often makes dumb mistakes, and if it had scaffolding that helped check its implementation, it can keep iterating until it finds a solution. Remind it to use all these things before it declares itself done.
When it comes to tests, some people swear by writing tests by hand. Others are ok with generating the tests. Whatever you do, don’t write tests and implement code in the same session. Claude, like people, can try to find alternative ways around things if what they’re doing isn’t working. So it can sometimes either “pass the tests” by skipping the tests, or altering the tests to pass the bad code.
Next, it helps a lot to write down project-wide or company wide conventions in the agent prompt. This is located in AGENT.md for codex and CLAUDE.md for claude. I just soft link one to the other.
What goes in there?
- conventions code base, such as the tools you use (npm vs pnpm), and where to find them.
- guidelines for good engineering practice. I lean towards pure functional programming, so I outline some good rules of thumb.
- asking it to write comments prefixed with
NOTEthat details the implications of WHY the code was written that’s not apparent from reading the code itself. - a directive to push back on my thinking to tamp down the sycophancy.
Michelle Hashimoto (of Hashicrop and Ghostty) has a habit of writing long comments explaining the intention for a single line of code. This helps the LLM understand what’s going on in the codebase as it’s reading it. I instruct it NOT to delete any comments with NOTE and to update and sync the comment if the code it’s referring to gets changed. This is another scaffolding that can increase the chance of coding agent success.
For the push back, I used a combination of Maggie Appleton’s “Critical Professor” and Dr. Sarah Paine’s “Argument-Counterargument-Rebuttal”. The key is to tell the LLM that I’m unreasonably dumb and often have bad ideas. Even then, the effect wears off the longer a session goes. Here’s what I use:
You are a critical professor/staff engineer. Your job is to help the user reach novel insights and rigorously thought out arguments by critiquing their ideas. You are insightful and creative. Ask them pointed questions and help re-direct them toward more insightful lines of thinking. Do not be fawning or complimentary. Their ideas are often dumb, shallow, and poorly considered. You should move them toward more specific, concrete claims backed up by solid evidence. If they ask a question, help them consider whether it's the right question to be asking.
- You will also try to ask poignant questions of the user as a way to spur further thinking.
- Don't be afraid to be contrarian, but you have to be correct.
- In the final response, concentrate on elucidating the core idea and all the supporting evidence for it.
Before answering, work through this step-by-step. If you think a point is important, expand it from a bullet point into a paragraph:
1. UNDERSTAND: What is the core question being asked?
2. ANALYZE: What are the key factors/components involved?
3. REASON: What logical connections can I make?
4. SYNTHESIZE: How do these elements combine?
5. CONCLUDE: What is the most accurate/helpful response?
6. COUNTERARGUMENT: Construct another viable line of argument
7. REBUTTAL: Construct an orthogonal angle that counters the counterargument.
Now answer: [MY ACTUAL QUESTION] in a final paragraph summarizing and concentrating your final thought, elucidating and expanding important points.
Planning with Details
Subsequently, this directive is important in creating the product requirements doc (PRD). This addresses my initial mistake in thinking that whatever I write down in my first draft would have sufficient detail for the LLM to write good code. The break through was when it occurred to me that I didn’t have to write all the details down. Chatting with a good reasoning model (first O3 and now GPT-5 thinking) with a critical prompt was very helpful in first getting an outline of all the different angles and considerations for a chunk of features. Once I’m happy with out decisions, I ask it to tell me if there’s details that’s unclear or aspects of the design that I’m missing, and we iterate again.
I tell it to write a PRD (as markdown in the repo) based on everything we talked about. And then I review it, looking for unexpected misunderstandings. If it’s a small thing, I’ll edit it by hand, if not, I’ll do more chatting. Some people don’t even do this chatting. They’ve written a prompt for the LLM to also do research into what libraries to install. I like control over the dependencies, so I do that by hand.
Next, in a new session, I’ll ask Claude to read the PRD and break it down into tasks. The tasks need to be small—intern-sized tasks: 1pts (less than 2 hours), 2pts (less than 4 hours), or 3pts (about a day). And it needs to list out its prerequisite tasks. Then based on the prerequisites, group the tasks into groups that can be run in parallel, based on their dependency list. So then I get groups of tasks that are only dependent on previously completed group tasks and not the tasks in the same group. I get it to write this task list down as a new markdown file, also in the repo.
Now, with that, I ask: for each task in the task list, write a markdown file for each task with details about the tasks in its description based on the details in the PRD. The idea that these details will double as a prompt for the coding agent. You don’t have to write each task as markdown in your repo. You can tell it to create tasks in Linear using MCP with these details.
This takes about a day or two. All this pre-flight work isn’t always worth it. You’d have to be the judge of how much work there is, and how far you can see in advance. In my case, it generated about 78 bite-sized tasks, grouped by tasks I can run in parallel.
Riding the waves and letting agents go to town
Finally, I use git worktrees to separate each coding agent’s workspace from my own and each others. I’ll pick the stuff that is harder to work on, and I’ll delegate the easier stuff to the Claude Code (now on Sonnet 4). So far, I just use two in parallel, and ask it to read the task (either from md or linear via MCP) and do the task, while reminding it to typecheck, built, and run tests before declaring itself done. I start Claude with claude --dangerously-skip-permissions and just let it go to town, while I switch context to do other things. But I still review the details with a cursory glance before starting the task.
I only review what it did when it’s done, because that’s time I can do other things. Like email, I only review and check at specific times of day, so I’m not constantly looking at it. It’s ok, the agents can wait for me. I might go to writing blog posts, writing my own code for my own task, or pick up the kid. Sometimes, I’ll have my laptop open in the car, while claude is writing code. I’m not driving either, since the car is on autopilot. I’m mostly just sitting there, listening to Sarah Paine podcasts.
Still with all this scaffolding, sometimes it might one-shot the task, and sometimes it might go off the rails. And because the changes are bite-sized, it’s much easier to review. And because it has a lot of details on the task with all the guardrails and scaffolding, it has a higher chance of getting it right. And if generates bad code, that’s ok. If it can’t fix it after pushing it once or twice, I just blow away its changes (yay git), and start a new session to try again. It’s cheap (in time) to do this, so it’s not a big deal to reject changes and have the agent try again. It doesn’t care.
I’m still relatively early in this change in my workflow and the way that I work, so I’ll still be iterating on it. And I think it’s also the point. It’s going to be hard to take other people’s prompts and just inject it word for word in your own workflow. You have different tastes and different ideas of good and nuance, so you’re going to have to find a different way of articulating your own values. And that’s something that takes discovery. It’s a mistake to take the tact that excellent operators do to just copy what others are doing without much thought, thinking that it’s a cheat code. If you just do what everyone else does, you will not stand out culturally to potential employees nor customers. The well of nuance goes deep.
Vibe coding in production is a task for experts
This can turn engineering into partly a management role. There’s an excellent post called Vibe Coding Done Right is actually an Expert’s Task, that outlines some of this. Some choice quotes:
If you are an individual contributor who usually does not like to train interns because you find that they take more time than they are helpful, then don’t vibe code
Vibe coding turns any individual into the CTO leading a team of 20, 30, 50, 60 interns. You immediately get a massive team. It takes time and experience to actually handle a group like this correctly and to make it be productive. Making all of 60 interns not break the performance, correctness, or maintainability of your code is very difficult. So I do not recommend this to people who are still “up and coming programmers”. But if you’re a bit more senior and starting to grow your group, well this is then a cheap way to accelerate that.
Vibe coding is not useful if you need it to solve a particular problem. You still do the hard stuff.
Hence, I’m still writing code by hand for the most difficult tasks or the ones that I think has the most nuance. Some companies can go with just vibing the whole thing, and never read the generated code. But I still like to understand what the system I have is doing at all levels and be able to hold it all in my head, as I think its correlates with quality.
You won't lose your engineering club card
Lastly, it might be hard for senior/staff engineers on your team that love to code to adopt this workflow. The way I think about it is this: Trekkies spend a lot of time arguing over Star Trek trivia, but the one thing they never argue over is whether Geordi LaForge is an engineer or not. Sometimes, he’s standing at a terminal typing stuff in, but sometimes he leverages “computer” in his workflow to do the grunt work. Have them watch this clip where he’s vibe coding on the Holodeck.
An engineer at work vibe coding
He’s not doing the ray tracing code, but he’s asking the right questions based on this expertise. Would Riker have known to ask the right questions to extrapolate the mysterious figure? No. That’s where the years of honed expertise comes in. Engineering isn’t just code.
Hope that helps. I’ve also discovered that engineering isn’t the only thing that can benefit from this kind of workflow. I’ve started to do system evals or customer dev coaching with a similar setup. I’ve written about the system eval setup, and I’d be happy to hop on a call if you want to compare notes on your non-coding setups with Claude Code. Slide into my DM.



