The moats are in the GPT-wrappers


Despite the disdain for "GPT-wrappers," it's currently where the value is accruing in the supply chain of value to the end-user with LLM-driven apps. Unless something changes with the foundational model companies approach the market, the GPT-wrapper application layer is where the value accrues, hence where the money will be made. Furthermore, the application layer's moat will grow stronger due to the domain-specific contextual data and system evals that GPT-wrappers will create while operating within that layer.
Where does the power to command profits lie?
First, let's back up. Clay Christensen is well-known for his work on putting together a framework and lens on the Innovator's Dilemma (why incumbent firms fail to address threats from new upstart firms leveraging new technology) and the Job-to-be-done (how to view what value means to customers). But he has a less well-known framework called the Law of Conservation of Modularity (previously known as the Law of Attractive Profits)
This wordy name contains a simple idea: for any supply chain that delivers value from raw origins to the end-user, the amount of power each part of the supply chain can exert to capture this value (and hence make money) can never be created or destroyed–it can only be shifted from one part of the supply chain to another. As one part of the supply chain is commoditized and modular, another part of the supply chain becomes the critical integration point. That critical integration point becomes the hard part of the supply chain. It's the part that captures the lion's share of the value. [1]
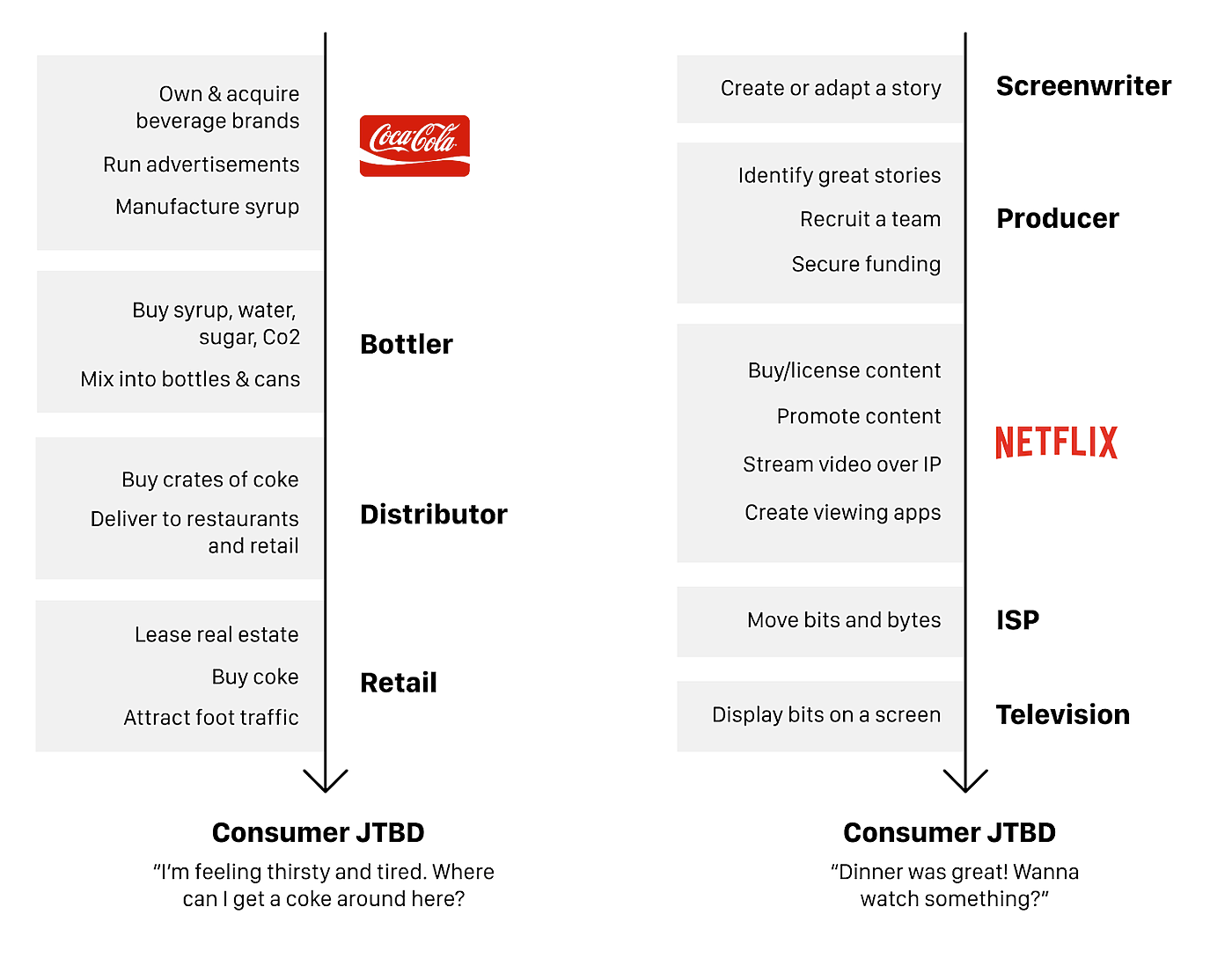
By "hard", I don't just mean technically hard, but that no firm can replicate what it does. At that point in the supply chain, the supply of whatever that firm does is limited. Given the basic economic dynamics of supply and demand, those who control limited supply can dictate terms when working across the supply chain. For brown fizzy drinks, it's the brand and advertising that's hard to do and reproduce by other firms. For moving picture storytelling, it's the content licensing and software to stream and view content that's hard to do and reproduce by other firms. [2]
Two ways of making money
But the dynamics of this supply chain aren't static. New disruptive technologies can shift the balance of these dynamics making one part of the supply chain way easier to do and more commoditized than another. When that happens, the hard part of the supply chain shifts, and new firms that discover what's hard can start to put together a solution that integrates those parts to make it easier for the rest of the supply chain to consume. This is typically called bundling. And when there aren't too many other firms that can do that part of the chain, that's where the power to dictate terms and capture value (and hence profits) will arise.
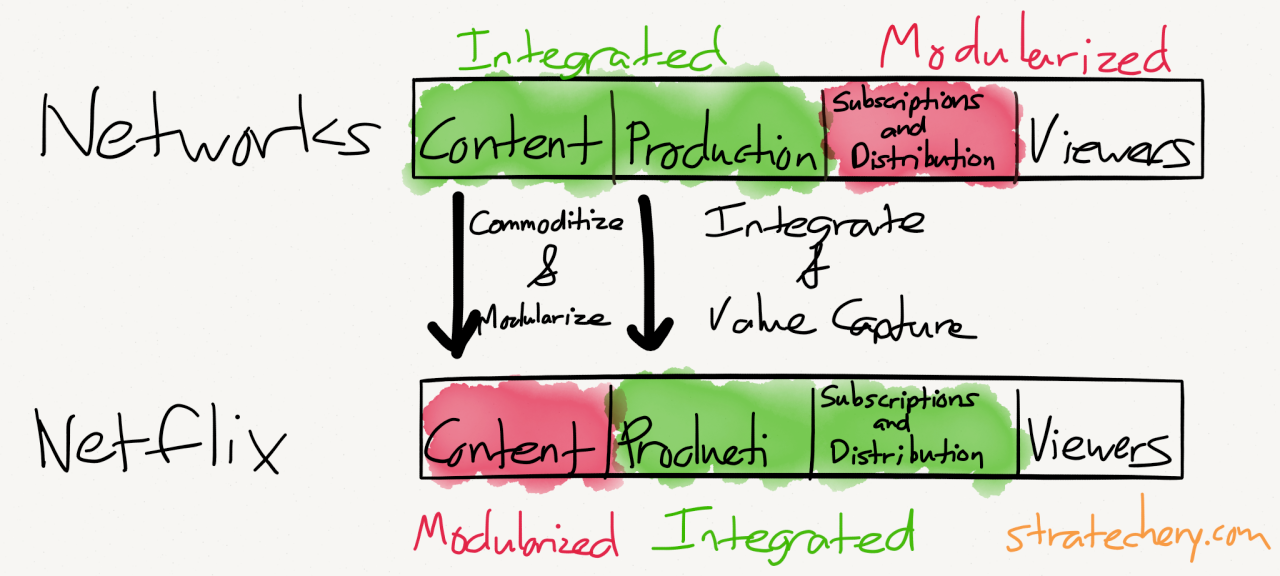
Bundling isn't the only way to shift the power dynamics of the supply chain. When an integrated solution has been around for a long time, people start using it for more than what was intended in the beginning, and they discover the edges of what it's good at and not good at. Over time, underserved niches by the integrated solution arise. Then, new firms can leverage technology to specifically target these underserved niches. This is typically called unbundling.
This bundling and unbundling dynamic is happening all the time, with new firms leveraging new technology to wedge themselves in a position to dictate terms and command profits.
“Gentlemen, there’s only two ways I know of to make money: bundling and unbundling.”
- Jim Barksdale via How to Succeed in Business by Bundling – and Unbundling
In the age of AI, the same dynamics are at play
These economic dynamics don't change now that we have AI through the implementation of LLMs.
Facebook released their Llama 65B parameter model to the public as open source, not because, as Mark says:
But overall, I just kind of think that it would be good if there were a lot of different folks who had the ability to build state-of-the-art technology here, and not just a small number of big companies...So, I do think that will be available to more folks over time, but I just think like there's all this innovation out there that people can create. And I just think that we'll also learn a lot by seeing what the whole community of students and hackers and startups and different folks build with this.
- Mark Zuckerburg via Interview #383 with Lex Friedman
Instead, it's a strategy for Meta to commoditize their complements. LLMs are not where they're making their money, and Meta sits on a different part of the value chain, so it's in their interest to do so. Zuckerberg may believe those things, but it's also aligned with his interest to believe so.
You can see Facebook taking a different stance with their VR headsets. Currently, the critical integration point of that supply chain is making the VR headsets, and they want to sit at that point as a hardware platform and charge app developers the privilege to develop on it, much the same way Apple does with its 30% tax on iPhone app developers and the way Microsoft did with its Windows developers in the 90's.
In fact, this kind of dynamic in VR dissuaded me from working on anything in the industry, even though I thought it very promising after some exploration. By depending on a closed platform that sits at a commanding part of the value chain, you're at the mercy of the platform owner, a position you never really want to find yourself in.
So when I first considered jumping into the fray of developing LLM-driven apps, I was afraid of the same dynamic as the VR. If OpenAI had the best foundation model, wouldn't that set up the same dynamic? When I raised this issue, most other founders didn't think about it much and dismissed it readily. But in the end, they were right (though I don't give them credit for being right for the right reasons). I had too heavily weighed the technological prowess of OpenAI as a moat.
A non-exhaustive list of what I didn't consider:
- The fundamental technology underlying LLMs is the transformer, an openly public paper anyone can read and implement.
- Teams of researchers working on this at OpenAI were idealistically driven. As soon as the organization turned its gaze towards productization and profit under the guidance of Sam Altman, there were defectors. Defectors meant new competing companies.
- Open-sourcing foundational models is a typical Commoditize your Complement strategy a Big Tech company could employ. Turned out it was Meta that did this. By open-sourcing a competent foundational model, the swarm of specialized open-source developers could advance the state-of-the-art much faster than any single company could.
- Once open-source foundational models were out there, model companies like OpenAI were no longer the critical integration point, and hence command no pricing power. The leaked Google Memo details this in “We Have No Moat, And Neither Does OpenAI”.
While there are many factors, I think a strong indicator that this is happening is that foundational model companies are in a bitter pricing war. The price per million tokens continues to drop precipitously, even as models get more capable across all models from all companies.
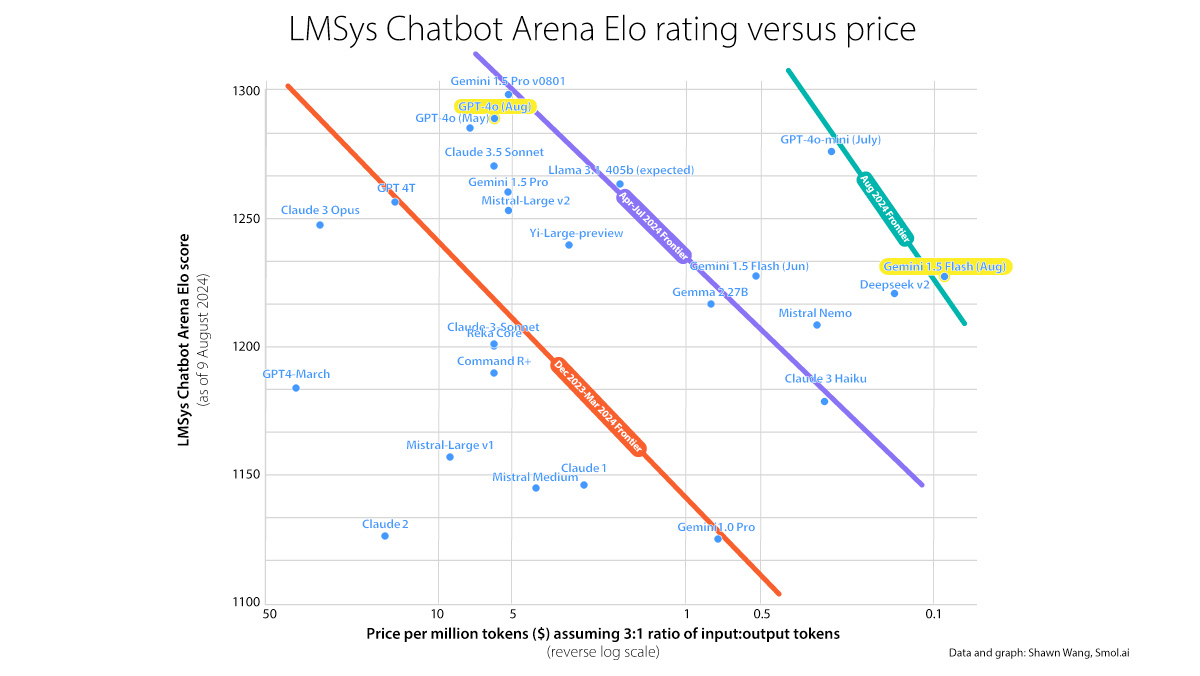
Sam Altman made the rounds with various heads of state, seeking more regulation by lawmakers. OpenAI seeks regulation for AI not because of an existential risk to humanity, but because the moat to their business is shallow. And just looking at OpenAI we can see the shallowness of the moat as exhibited by the price for the GPT-4 level model: it just keeps dropping.

So if the value isn't accruing at the foundational model, where is it accruing? Where in the supply chain of intelligence-on-tap is the power to command prices and capture value?
Value is captured at the GPT-wrapper layer
I think the value is currently best captured at the GPT-wrappers layer. These are apps targeting specific domains and niches using foundational model AIs to solve the specific problems users in that domain. I think this is true from a couple of indicators.
First, while a foundational AI model can cover a large swath of different tasks, for any specific domain a foundational model isn't going to be superb at it. It can (impressively) reach entry-level quality of work, but it has yet to bridge the gap to the 10x expert-level work across many domains.
From experience in a domain I know well, out-of-the-box foundational models aren't that good at programming. They're great for replacing junior devs and React web apps where there's tons of training data and the solutions are rather boilerplate. However, I find that they're still lacking in architectural design decisions and taste in systems engineering that a senior dev has to tackle. I've seen it struggle for a variety of reasons. These reasons are sometimes basic like the documentation on Zig in its latent space is outdated or it's not seen enough training data on how proofs are written in Isabelle. At other times, it's just not taking the rest of the code base into account in the solution it tries to implement, or it'll cycle back and forth between two bad solutions.
I don't think this lack of expert-level competence is limited to the domain of programming, as I've heard similar stories in other domains, such as corporate tax preparation and writing. There's still a gap. But how we close that gap will matter for who in the value chain will be able to best capture value.
Private context data is a moat
One way to close this gap is to augment an LLM prompt with the correct context for the domain by fetching relevant data from a database based on the user query. This is good 'ole 90's era Information Retrieval rebranded as RAG (Retrieval Augmented Generation). While it feels a bit like a stopgap, it works fairly well. Once LLMs have the correct context for a domain in their prompt, they do a great job of providing the correct answer.
It's currently GPT-wrapper companies, not foundational model companies, that are bridging the gap between out-of-the-box LLMs and user needs using RAG techniques. Not only that, the domain-specific context fetched from RAG databases is often private data obtained by GPT-wrapper companies as a by-product of doing business in that domain. Email marketing companies have a lot of private data on effective emails with high open rates. Social media companies have a lot of private data on posts that generate high engagement. E-commerce companies have a lot of private data on consumer buying patterns. This private contextual data that closes the gap to customer needs becomes a moat for the GPT-wrapper companies. And by the nature of being private, it isn't easily replicable by other companies in the value chain.
Another way to close this gap is to put this domain-specific context into the foundational models. That would require foundational model companies to have access to domain-specific private data being collected by GPT-wrapper companies in every domain. Foundational model companies currently train mostly on public data found on the internet, and it seems unlikely they'll spend lots of money licensing private data on top of the money they're already burning on compute for training. That said, I wouldn't put it beyond Sam Altman to strike a deal with these companies to let them subsume their private data into OpenAI foundation models. He's good at that sort of stuff. But as it stands, by default, foundational models subsume public internet data, and that doesn't make the foundational models exceptional in any one domain.
System eval is a moat
Second, GPT-wrapper companies have a unique advantage: their close interaction with users in a specific domain. While many today rely on "vibes-based engineering" to gauge if their LLM-driven app meets user needs, this proximity allows them to gather valuable feedback on what "good" looks like across a wide range of user queries. Often, we can't exactly write down the rules of why something is "good", but we can gather examples of what "good" looks like. Using this database of what "good" looks like to evaluate how well your system is servicing user requests is called a system eval.
Using system eval is what GPT-wrapper companies use to make sure they're servicing user needs. By meeting customer needs, they keep the retention high and the churn low. And because the database of examples of "good" could only be obtained through contact with the end-user, system evals become a moat. In addition, if a company has set up system evals as part of a systematic, repeatable process to continuously improve their product, it becomes a flywheel that will accrue competence that becomes impossible for other firms to replicate or surpass.
Lastly, as a small indicator, when I see AI consultants on Twitter saying they can charge six figures for a two-month stint for RAG implementation and services, I know that a) it's not foundational model companies paying for the service b) GPT-wrapper companies have the money to spend.
Commoditizing your complements
Despite the fame and acclaim, I think OpenAI, Anthropic, and other foundational model companies are not in a great business position. Now, this can change, and there are any number of moves to make, one of which is regulatory capture. But it can also try to commoditize their complements.
Commoditizing Your Complements is a classic from Joel Spolsky's "Strategy Letter V" that relates to the Law of Conservation of Modularity. It says the way to maintain your moat is to give customers free or cheap options in adjacent parts of the value chain. This is a strategy by which a firm sitting at the critical integration point can keep raking in profits by commanding the power to dictate terms to the rest of the supply chain. [3]
For example, Google actively gives customers free options in other parts of the supply chain for a user's job-t0-be-done of "going on the internet." It did this by actively expending the effort to write open-source software like Chrome, making the internet accessible everywhere, or making cheap and alternative smartphones. [4]
Foundational model companies could take a page from Google's playbook and start entering other domains with free products to increase the use of intelligence on tap. It could conceivably use LLMs to generate domain-specific applications to enter into these specific domains and charge nothing. This is then used to gather feedback and evals to systematically improve results, and feed that back into the foundational model. If on the way to AGI, OpenAI decides to launch an email marketing app to help with marketing campaigns, a programming IDE to help write apps, or a tax preparation app–all for free–I wouldn't be surprised.
GPT-wrapper is a misplaced pejorative
I think "GPT-wrapper" is a misplaced pejorative. The hard and un-replicable part of the value chain isn't the tech of producing an answer, but data that's needed to produce an answer. Given current value chain dynamics in late 2024, it's great for 3rd-party developers. It'll be some time before foundational model companies get around to pulling themselves out of a nosedive by realizing the way to go isn't to make better foundational models and compete on price. They might be trapped by their rhetoric and vision to "get to AGI". But before then, GPT-wrapper companies need to wake up and finally realize the fact that they're in a great position to be the critical integration point in a supply chain of value to the end-user, if they move away from vibe-based engineering and get started on doing system evals to cement their moat.
Like Garry Tan of YCombinator says:
Don’t rawdog your prompts! Write evals!
- Garry Tan
So disclaimer: a friend and I did write an eZine on how to do system evals. This wasn't meant to be a long ad for our system eval zine. I only wrote this because I thought someone was wrong on the internet, and it had to be said. But even if I hadn't written a system eval zine, I'd still take this position.
Hence, take it or leave it. But to those for whom this is relevant, the ROI cannot be understated. A proper moat is worth millions.

[1] This is covered at length with Finding Power and Netflix and the Conservation of Attractive Profits – Stratechery by Ben Thompson to get some background under your belt.
[2] Yes, both Coca-Cola and Netflix have competition within their layer. Coca-Cola has Pepsi, and Netflix has Hulu and Disney+. The Law of Conservation of Modularity compares firms across the supply chain that delivers value.
[3] Made the connection recently after reading both "Law of Conservation of Modularity" and "Commoditizing your Complements" many years apart. However, I never read any writing online that connected the two. You can tell me if it's obvious or not.
[4] The analysis for "Commoditize your Complements" is also covered at length by Gwern, for those of you who like rabbit holes.



