System eval with Obsidian and Claude Code


Lately, I've been experimenting with a different system eval stack than what you might normally hear about: Obsidian and Claude Code.
Typically, Obsidian is used as a personal note taking app/knowledge base and Claude Code is used as a coding agent. I'm misusing both to hack together a system eval without having to deal with a lot of infrastructure set up.
The tools
I'm using Obsidian to document the eval process as a markdown file to make it repeatable. With it, I can see the entire process laid out and I can link the data and different parts of the process. I can start and redo any part of the process.
Claude Code can then make parts of it "executable". For example, every stage in my eval is a section, and each section is a prompt. I can use Claude Code to read that prompt and execute it.
The structure
Processes are imperative by nature, usually a step-by-step recipe for doing something, to transform data into a format or computation that we need. They can be more complicated, with branches and conditions, but for the most part, processes that you'd write down in a document is organized linearly.
The system eval process is iterative, but if you don't explicitly draw the re-iteration arrows, it can be laid out sequentially. Every step of the system eval is a section, and a section has a couple main parts:
A section of the eval
Each section has:
- A prompt for generating the next stage of data (or a the script that computes the next stage of data.)
- A command line on how to run the script
- A link to the listing of the output.
For example, here's a preprocessing step, where I convert the user queries into traces. But instead of writing the python script myself to do it, I just write out a prompt to one-shot the script.

In order to run the prompt, I then go into the terminal and run Claude Code. Then I ask it the following:
Read the prompt from `Create Traces from Queries` section of @pages/Product Expert for Sales Safari.Eval.md and do what the prompt says
It's able to go into the knowledge base (because they're just files on disk!), find the appropriate file, find the prompt in the appropriate section, and then follow the prompt and one-shot a script. I find that these scripts are simple enough that Claude can get them right, if you just write pseudocode of what you want.
After generating the script, I can then run that script to create a set of outputs into a directory. I use the documented command line to run the script, such as
python3 scripts/convert_discord_json_to_md.py sources/lesson_1 queriesAnd then use that as in the input to the next section with its own prompt and script.
Error Analysis
I can see the list of the output of traces in the directory from Obsidian. And each trace is just another markdown file. I have frontmatter that has fields for judgement and annotation, so for now, I'm just doing error analysis that way, rather than vibe coding an app.
Claude Code isn't always for one-shotting a script. When I need to get it to categorize axial codes from a list of failed traces, I can write the prompt in Obsidian and ask Claude Code to run the prompt. And if I need to redo it, I can have a repeatable way to keep track of the prompt I used.

The salient point
In a way, it's like a poor man's notebook with AI in it. This setup has the following benefits:
- I have a layout of my entire system eval process and I can re-run them in a repeatable way when I need to. It's too easy to do system evals as an ad-hoc set of prompts and results you think you'll never need to rerun again.
- With the eval process in Markdown, it's easier for me to show and share with other people without needing them to install anything or get them an account.
- Markdown is just text files, so I can version control it with git.
- The volume of data isn't crazy, so I don't need a database. I can just write them in files and work with human-readable text.
- If you have system prompts or other knowledge you'd want Claude Code to take into account during a prompt, you can write it in the knowledge base, and tell Claude Code to look for it.
The last point is especially salient. The fact that both Obsidian and Claude Code work on the ubiquitous markdown file format in the file system means that it's a narrow-waist format, like how IP (and increasingly, HTTP) is the Narrow waist of the Internet.
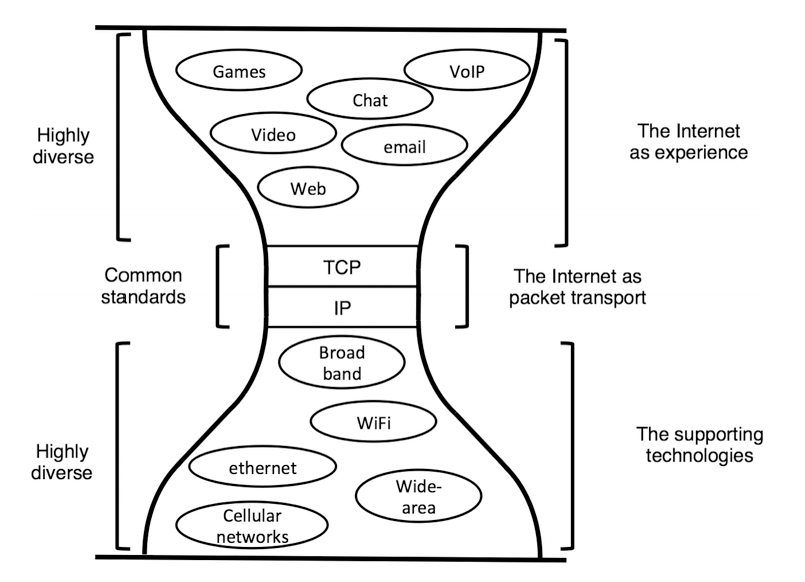
Usually, attempts for a narrow waist are hard to do, unless they were designed from the beginning. Obsidian leveraged files because it didn't want the lock-in with Roam Research. Claude Code leveraged files because the medium of programmers is the text file. But in this lucky happenstance, both Obsidian and Claude Code leverage a common format that explodes the flexibility and possibility in ways we've forgotten since we've used apps and web apps for so long.

The ability for an agent to have access to an entire knowledge base in order to finish its task was pretty eye-opening for me. Where AI fails is often a failure of context, rather than ability. I think people are still catching up to when AI does well and when it doesn't. For AI, context is everything, and providing the right context is most of the battle.



