Lab note #044 Sailing by cache-oblivious data structures


As part of biasing towards action, I thought it was time to reimplement the Prolly Tree in Zig. I wanted to focus on being cache-friendly this time, now that I have lower-level control. But that resulted in a deep dive into data-oriented programming. The question is how to represent a tree in a data-orientated way to best utilize the cache? Most resources seem sparse on this, so if you know an answer, let me know. My search leads back to the MIT courseware lectures on Cache-oblivious data structures.
Cache-oblivious data structures base their Big-O on the number of cache line transfers between different levels of the memory hierarchy to minimize its growth as the data set gets bigger. I started reading papers on Cache-oblivious data structures to get a handle on it.
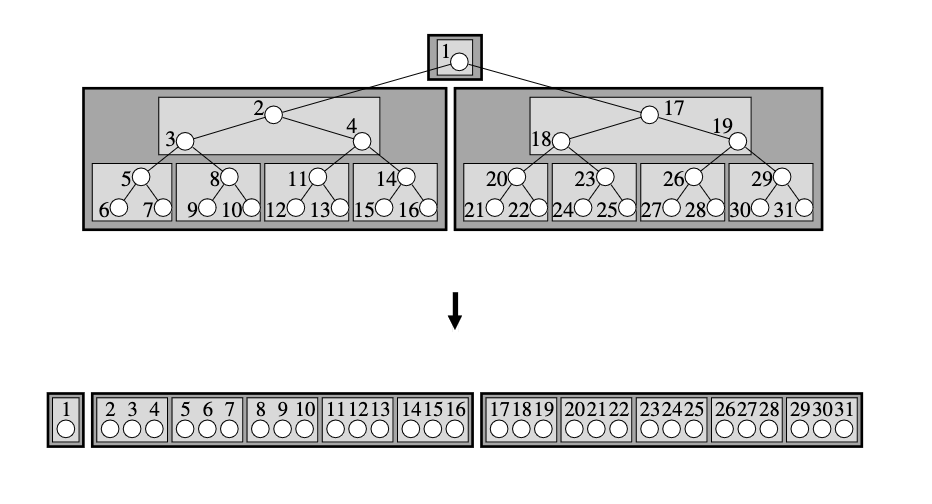
Through it, I learned about the van Emde Boas Layout. It's a linearization of a tree that's supposed to minimize the number of cache transfers in the ideal memory model by being fractal. For typical traversals, the distance from one index to the next is not as far.
But the idea is 25 years old. If cache-oblivious works as advertised, why haven't I heard of any modern databases using it as an index? The only thing I found was on Wikipedia, about how it's not actually a 10x improvement.
I was perplexed about this. Why doesn't something with the theoretical means to be optimal do so poorly? I put out a tweet thread with some thoughts on this.
Modern computers are so mind-bogglingly fast. But overwhelmingly we write software that results in a user experience of waiting on slow software.
— Wil Chung (@iamwil) July 4, 2024
What gives?
A wandering 🧵 on modern CPUs, OOP, B-trees, cache-oblivious, and local-first.
I got an offer to chat with Predrag Gruevski. Two things I got out of the conversation:
- van Emde Boas layout sounds good on paper, but it has a large constant time.
- It all depends on the access pattern. It pays dividends to set up a test harness where you log a trace of the operation to compare apples to apples on different data structures.
In addition, I started watching the 14th lecture on performance programming. Most of it wasn't applicable, but it did say that theoretically optimal is just the first step.
It's a pity that cache-oblivious data structures don't work out, because it seems like this is related to local-first software. One of the open questions is what to do when the entire working dataset doesn't fit on the client. This may not be a problem for personal productivity software. Git has also demonstrated that code bases are going to fit on the client. Text just doesn't take up that much space.
But for video and image apps or Web 2.0 style collaborative sharing, the working data won't fit on a client. Sometimes, there are distinct boundaries you can draw, like the latest day's worth of posts, like in a feed. But sometimes, the data doesn't have a relation that makes a clear-cut boundary like that.
The memory hierarchy model and cache-oblivious data structures can extend to viewing the network as part of the memory hierarchy. Hence I would think the theoretical principles of cache-oblivious data structures could extend to include the network. That way, we can be guaranteed theoretical bounds on the number of transfers over the network in order to serve a query on an index.
However, that's just speculation on my part. Someone will have to do the work to find out. In the meantime, I'll keep going with a prolly tree, unless I find something better. I saw on a lobste.rs thread about pq-tries and crit-bit trees. No idea what they are yet, but they're just leads.



