Lab note #049 Survey of Reactive and Incremental Programming


For a while now, I've been circling the drain on the Tools for Thought space and all the topics related to it. One large topic is reactivity, and not too far behind is incremental computation. They're two sides to a coin, so it's hard to disentangle them from each other. I spent this past week, doing a survey of all the notes I took on this topic. I want the notebook to be reactive: When a user changes something, it should update the state and output of the notebook to the furthest computable state and output.
Reactivity is a loaded term. I hesitate to say Functional Reactive Programming (FRP) because the original meaning is different than what we would take it to mean from just the name. According to Conal Elliot, the originator of the term, FRP has only two main ideas:
- Design the library with denotational semantics, rather than operational semantics. In other words, the spec should be about its meaning, rather than what to do step by step. This is what functional in FRP meant, since functional programming originated heavily from math.
- Model the incoming data as a continuous value, rather than discrete values. This makes it easier to join or merge signals, without worrying about the effects of discretization. This is what the reactive in FRP meant.
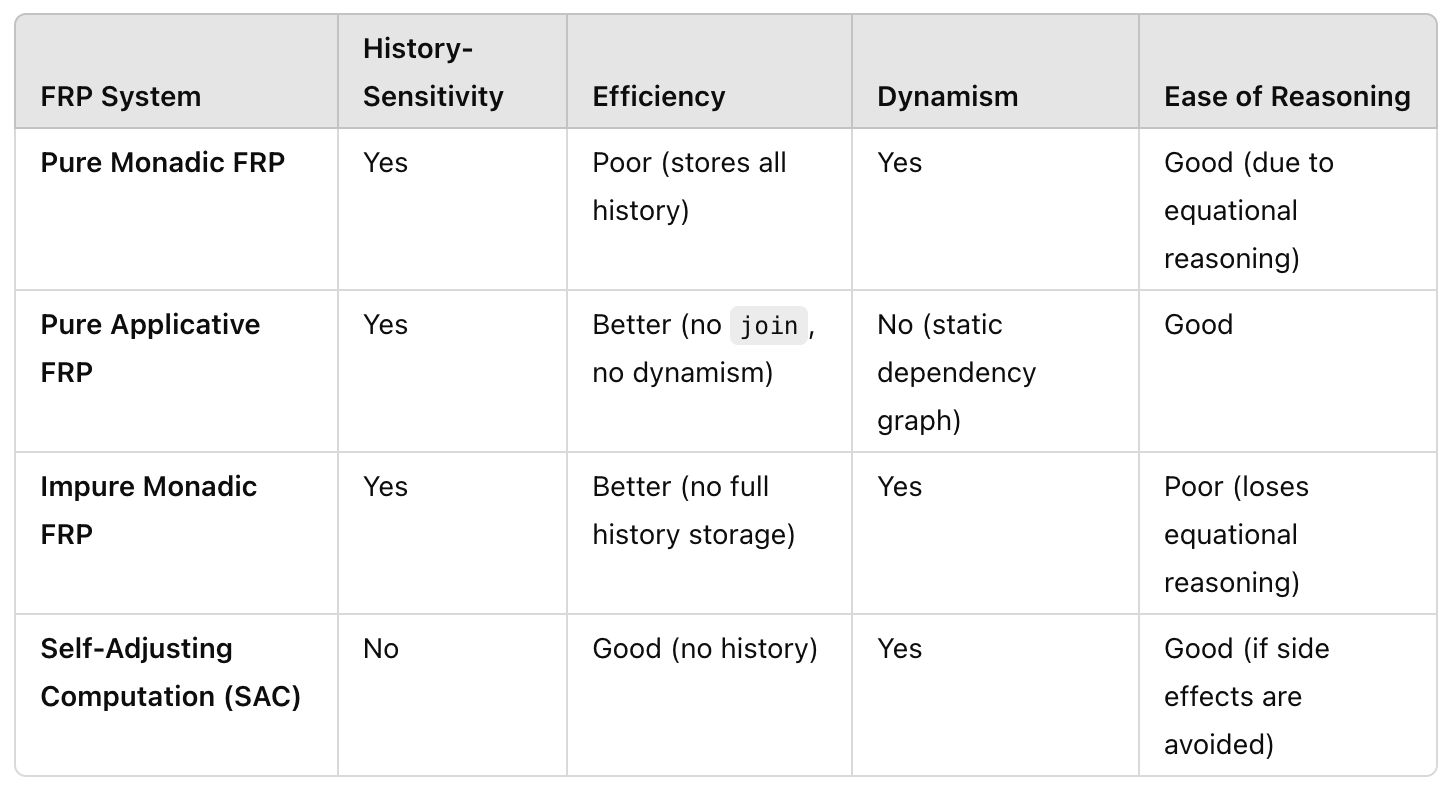
To the originator's lament, most people focus on the other aspects of FRP, from the computational DAG to representing everything as a signal. In Breaking down FRP, Yaron Minsky (from a talk by Evan Czaplicki), categorized FRP as having a different set of properties that all have trade-offs.
- History-sensitivity, or the ability to construct calculations that react not just to the current state of the world, but also to what has happened in the past.
- Efficiency. This comes in two forms: space efficiency, mostly meaning that you want to minimize the amount of your past that you need to remember; and computational efficiency, meaning that you want to minimize the amount of the computation that must be rerun when inputs change.
- Dynamism, or the ability to reconfigure the computation over time, as the inputs to your system change.
- Ease of reasoning. You’d like the resulting system to have clean semantics that’s easy to reason about.
For me, the only reason I'd care to engage with the added complexity of such a system is to give the user immediate feedback for changes in a timely manner. I had originally thought What is Reactive Programming? a rather thin explanation, but on second thought, it does embody what I care about with reactive systems:
When the user makes a change, the system should move the state and output of the system to the furthest frontier of the computable state and output in a timely manner–ideally almost imperceptibly to the user.
An underlying assumption of reactive programming is that the full computation would take too long to do. This is where reactive programming has a connection with incremental computation. With incremental computation, we try to find ways to do a partial computation to achieve the same output, which should drop the amount of time required.
Build systems à la carte was a good framework for thinking about these systems. It brought together the idea that build systems and spreadsheets are actually quite similar. You can categorize them along two dimensions: the type of scheduler, and the type of rebuilder.
A scheduler's job is to reorder the units of work so that computational dependencies are in the right order. A rebuilder's job is to decide whether any particular unit of work needs to be done, given its dependencies. A unit of work is just some portion of the computation. In typical runtimes, this might be a function, but in incremental computations, we can divvy it up in different ways.
This characterization gives you a sort of periodic table of incremental systems where, you can see, based on the types of schedulers and rebuilders that we know about, whether there are incremental build systems that are missing. While I won't go down that road here, this was a useful framing when I tried to see how other reactive systems did their jobs.
While UIs weren't mentioned specifically in A la Carte, React is definitely a reactive system commonly used today. After a refresher on how it worked under the hood, I could see the commonalities to build systems and spreadsheets. A unit of work is called a fiber organized in a tree that mirrors the UI tree of components. The scheduler is implied by how the fibers are organized with respect to each other, and the reconciliation is akin to the rebuilder. React is a little different, however, in that it almost has two different computational DAGs, or rather, we can think of the tree of components as a static computational DAG, and the hooks as a dynamic computational DAG that sits on top of it.
A system largely inspired by React is Live, the reactive system that drives Use.GPU. Steve Witten details it in many blog posts, but the one with the most concentrated detail is in Fuck It, We'll Do It Live. I haven't finished going through the entire thing yet, because the language is a bit hard to decipher. But here, I've found LLMs very useful in rewriting the posts with a bunch of explainers attached. Re-reading these, I realized there were insights that were skipped over when I read them the first couple of times. In The Incremental Machine, it poses the perspective that we mark dirty bits in incremental systems precisely because we don't know at the moment we marked it, how much to recompute. So we defer. In fact, if we squint a little, we can view a dirty bit as a poor man's async/await, or the resumption of a computation.
Moving on, the Self-Adjusting Computations mentioned in Breaking down FRP is a classic. Their formulation of Adpatons is a typical reference for incremental computational systems. Here, I find it also loosely fits into a similar framing outlined by A la carte. Its unit of work is thunks, the scheduler is implied with how the thunks are chained together, and the rebuilder is based on the cache of traces from the result of computing thunks.
You can take a different tact to incremental computation. Instead of relying on a computational DAG and finding a way to skip over unnecessary computation that won't change the output given the current change in input, we can instead limit the types of computation the user can do, that have certain desirable algebraic properties. This is what Automatic Differentiation does, as well as Differential Dataflow. I won't go too much down this road at the moment.
To go back to the algebraic effects system I implemented last week, I also see some parallels. The unit of work is the effects description that was raised. The part of the system that can decide to compose, batch, or reorder different effects is akin to a scheduler. The part of the system that finds handlers and executes them is akin to the rebuilder, though its job is a bit different--it doesn't try to reuse the results of computation. However, effects system isn't limited in that sense, it leaves the determination of whether to reuse computation results to the implementation of the effects handler.
As a bit of a stretch from last week, I wondered if a logic programming runtime would be similar to an incremental reactive runtime. In a Datalog runtime, adding a fact is akin to changing the input and running to a fixed point would be akin to finding the furthest frontier for the state and output. Or in Dynamicland's Realtalk (which looks suspiciously like a logic programming language), might it not be executable with an incremental reactive runtime?
I asked GPT for a comparison, and it gave me this table:
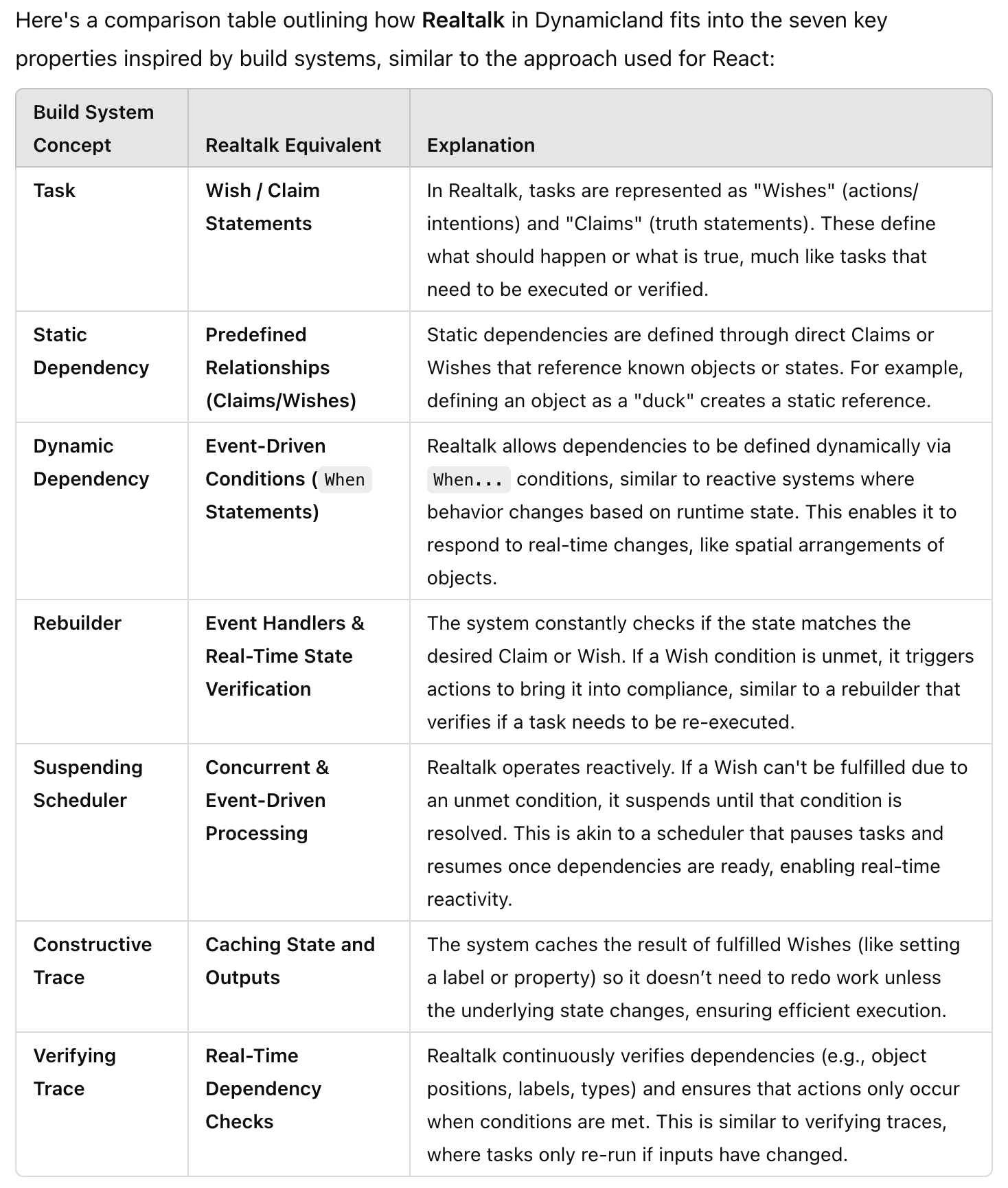
I think the connection is stronger than I can argue for at the moment. So for now, this will remain a curiosity.
With the survey, I think I have enough to go on for a basic reactive system. I think there's a bunch of challenges here, but the main outline is to:
- Define a unit of work that makes sense for breaking down the computation that needs to be done.
- Have a scheduler that divines the order with which the units of work must be processed
- Have a rebuilder that decides how to skip work that we don't need to do.
- And a resumption mechanism to resume computation after we obtain a result. Currently, I'm using generators, because that's what's available in Python and Javascript. And it's serviceable for now, but I suspect if I want to do anything concurrent, I'll need something like first-class continuations or something.
This next week's goal is to get something simple up and running.
List of some resources on Reactivity and Incremental Computing I looked at this week
- Responsive compilers - Nicholas Matsakis - PLISS 2019 - YouTube #[[Compilers]]
- miniAdapton: A Minimal Implementation of Incremental Computation in Scheme #[[Incremental Computation]]
- Your Mouse is a Database - ACM Queue #[[Database]]
- (148) ICFP'21 Tutorials - Programming with Effect Handlers and FBIP in Koka - YouTube #[[Koka]] #[[Algebraic Effects]]
- Building Differential Dataflow from Scratch #[[Differential Dataflow]]
- Adaptons and miniAdapton: A Minimal Implementation of Incremental Computation in Scheme #[[Incremental Computation]]
- Coroutine - Coroutines.pdf
- Build your own React #[[React]] #[[Reactivity]] #[[Incremental Computation]]
- Fuck It, We'll Do It Live — Acko.net #[[Reactivity]] #[[Incremental Computation]]
- The Incremental Machine #[[Steven Witten]] #[[Incremental Computation]] #[[Compiling Composable Reactivity]]
- Build Systems A la Carte #[[Incremental Computation]] #[[Simon Peyton Jones]]
- 2014 Minsky Jane Street. Breaking down FRP #[[Functional Reactive Programming]]
- (155) The Essence & Origins of Functional Reactive Programming • Conal Elliott • YOW! 2015 - YouTube #[[Conal Elliott]] #[[Functional Reactive Programming]]
- 2014 Minsky Jane Street. Breaking down FRP #[[Functional Reactive Programming]]
- What is Reactive Programming? #[[Reactivity]] #[[Compiling Composable Reactivity]]



