Lab note #066 But I don't want to write a compiler


I bit the bullet and went towards re-doing the effects system implementation with the native async/await, to see if I can get a baseline implementation. I was successful, but not without roadblocks along the way. This version is much simpler and handicapped than what I wanted originally, but I need to move on to validate some product hypothesis I have for myself.
Because to build the full-blown version--turns out to be the equivalent of writing a compiler/interpreter. That's a lot of work to put in before I'm fully convinced of the end-user utility.
Using native Async/Await
Many things are simplified using the native async/await. One major thing was not having to make decisions about the types, before or after awaiting. That's already done for me, and the only compromise was having to use the await keyword.
The thing that seemed nice was the driver for an async generator is just a for loop, instead of the API for a synchronous generator driver. But it wasn't meant to be.
Async generator cannot send values back to the generator
I ran into a major blocker: you can only send None into an async generator. That means there's no way to return the value of an effect handler back into the the effectful function. 😫
O3-mini claimed this was done so simplify the implementation in Python, and suggested the only other workaround was to create a task and insert it directly into the asyncio task queue. This is pretty much like implementing await, but with some control between scheduling and executing. This also means that handlers would be like daemons that kept listening to tasks on the queue.
If each handler was its own daemon, it wasn't clear how to make them select only effect tasks that it can handle, since asyncio doesn't provide a way to peek (without popping off) the task queue.
The only way this would work is if there as a single handler daemon that popped every event task off, and then tried to find the correct handler for the effect. In addition, we'd need an entirely different queue separate from the regular async execution queue, so we wouldn't need to filter out regular async functions. That also means running in a different thread, as there can only be a single event loop per thread. This wouldn't work in Pyodide running on WASM, and would rely on webworkers, which means complications with inter-worker communications. I've already tried that earlier and would like to avoid that work unless it was really worth it. For all of these reasons, I don't think it's a good way to go.
use perform() to raise effects
So then what if we just make it even simpler? What if we used async/await when raising an effect? We would lose the ability to abort in the handler. But at least we can resume a computation from where we raised the effect. If we don't use a generator, async/await is the only other ways to do single-shot resumption. The API would then look like this:
@async_reactive
async def fetch_async_data(self) -> dict:
"""Test function that performs an async fetch operation"""
result: Result[dict, Exception] = await perform(
Fetch_Async("https://dummyjson.com/products/1", mime.MimeType("application/json"))
)
return result.unwrap()On first glance, that doesn't seem so different than the previous API, where we used the effect name to dynamically execute a method with the same name. However, with all effects executed by the same method perform, by itself, it has no way of knowing what the return type is. That means the user raising the effect will have to remember, or cast it themselves.
To fix this, Claude suggested using a single overloaded method, perform with different effects passed into it. When that's the case, we get the following API:
@overload
async def perform(self, effect: Get[T]) -> T: ...
@overload
async def perform(self, effect: Put[T] -> None: ...
async def perform(self, effect: BaseEffect[Any]) -> Any:
...But after going down this road, I really didn't like the experience of building abilities. For one, you need to put the implementation of all different effects in the same function (or you put them in different functions, and route it in the undecorated perform) by using match or if/else.
In addition, you need to remember to raise an AttributeError if none of the effects can be handled by the handler. That's because if we overload perform, we'd need to use chain-of-responsibility, either by putting all the handlers in a list or in an inheritance hierarchy. That puts the onus on the user to remember to do bookkeeping, which is never a great API.
Handler look up using chain-of-responsibility
Because in a chain-of-responsibility with overloaded perform, the only way you can tell if a handler will handle an effect is by trying to call it, and if it doesn't, catching its exception. This is because @overload annotations only exist at static compile time, and disappear during run time.
It's much easier to just do some method lookup from the effect name. This was what I did the first time, and I thought I was just hacking it up. I went back to doing that, rather than this perform line of thought. This is what I mean when I say Generative AI is still bad at code architecture and design. It seems reasonable on the surface, but unless you go down each of the paths and work out why it sucks for a variety of reasons, you can't see why it just doesn't have taste.
No type checking for raised effects
I mentioned earlier that we have to explicitly cast the type of perform. We can fix this if we change the signature of Effect to be parameterized by its return type.
class BaseEffect[R](ABC):
return_type: Type[R]So that's fine.
But we have another problem. Because we no longer have a generator, we do not annotate yield types. Before, we could at least check that the Effectful function wasn't yield effects it didn't intend. But now, we can't tell if Effectful function are raising effects its annotation doesn't say it does.
We could annotate the return type with a tuple or a wrapper type that includes effects.
@async_reactive
async def some_node(self) -> Effectful[Get | Put, int]:
state_val = await perform(Get())
incr_val = state_val + 1
await perform(Put(incr_val))
return Effectful((Get, Put), incr_val)This is the same problem we ran into with ReactiveValues: when we rely on wrapper values as returns, we now we need a bunch of machinery to deal with monadic wrapper types in all our computation. I think in order to avoid the repetition of the tuple at the return, I'd have to be able to treat the entire computation inside of the node as a declarative build up of computation, so monadically, I can collect all the effects that were raised.
This does make a lot of semantic sense, and I think I'll eventually have to go down this road. I don't think there's any avoiding it if I want to separate the construction of a computation from the execution of it. The question is whether it can be seamless enough of an experience. I think this will take a lot of work, and I currently don't know if it's worth the investment. The more I dig into this, the more I think JSX was a genius move. The React team was able to hide the idea of a compositional and declarative description of a computation inside of what looks like a declaration of the view. [1]
Alternatively, we could annotate the __parameters__ of the reactive function with optional effect types.
@async_reactive
async def some_node(self, effects: None | Get | Put = None) -> int:
state_val = await perform(Get())
incr_val = state_val + 1
await perform(Put(incr_val))
return incr_valOr we could stick it in the decorator
@async_reactive(Get | Put)
async def some_node(self) -> int:
state_val = await perform(Get())
incr_val = state_val + 1
await perform(Put(incr_val))
return incr_valEither way, the return value is kept simple, so composition in the imperative style is kept the same, and we won't have to deal with composing monadic wrappers. And the annotation can be stored in async_reactive decorator and checked when perform is run, but that means there's no static type checking, which I think is a major affordance of effect systems.
And additionally, there's no dependent types so there's really no way to do an end to end type check from raised effects to whether handlers support it–that is unless we write a mypy (a typechecker in python) plugin, or our own linter.
For now, the best option for some modicum of type checking is just some basic runtime checks. It's not ideal because effects, like exceptions amount to spooky action at a distance, and it's made sane with good type checking. Otherwise, it's kind of a terrible experience.
Multiple resumption
I watched Richard Feldman's talk on Union Types for an Simple Effect System again, since this was the very problem I was tackling. The operations part was something I missed the first time around. In fact, he does have wrapper types to separate description from execution. However, he doesn't have a generalized interpreter. You cannot add new effect types, and a specific specialized state machine to execute the composition of effects.
But this lead me to a conversation with O-4.5 about the difference between using Free Monads and Algebraic Effects, but most importantly, I floated an intuition I had about the whole thing: If I implement wrapper types to separate description from execution, we get multiple-resumption and effect type checking.
Most languages don't have delimited continuations, so a clever way to fake it is to generate a description of the computation and re-run it from the top every time you want to resume. But the trick is to leverage ideas from reactive systems to skip over computational nodes that don't need reprocessing to get to the call site of the raised effect and resume from there.
This also lead to some exploration about whether it makes sense to use DBSP or Prolly Trees to represent this effect tree. DBSP would be great, but only if the effect tree is static, which I'm not sure if it will be. Prolly Trees would be great for versioning and comparison with the previous execution for skipping nodes. But in both, it's unclear what the right policy is for nodes with side effects. Do you re-execute even if the inputs are the same, because it's not expected to be idempotent? Or do you always re-execute, but only propagate results if the value is the same? Or can you get away with marking these effects as idempotent, and hope the remote server upholds this unwritten contract? I don't currently have these answers.
However, the problem is all this is a lot of work. It amounts to writing a compiler. For the first time, a programmer is saying, "But I don't want to write a compiler." At least not right now. Even though after exploring lots of different options in the design space, I'm living with the simpler implementation with more limited capabilities so that I can move on to the next part of the validation and get it to something I can use, before swinging back to address any of these things.
Here are the interesting links that I found this past week:
- A Field Guide to Rapidly Improving AI Products - Lots of AI teams think tools will save them, when the process of knowing exactly how you're improving is much more important. This is in line with setting up your evals correctly, which is why we wrote Forest Friends, an ebook on system evals.
- Cottagecore Programmers: The Idealization of Farming by Tech - I often joke that programmers too often quit it to go do woodworking. I think just the way that many are forced to work–speed at all costs, that many find alienation with their work, separated from their customers.
- Tracing the thoughts of a large language model - Really interesting probe into the inner workings of Claude. It helps to read these to get an intuition of how these things work under the hood at a high level. It's weirder that I would have thought. They don't just predict the next work. They refuse to answer by default. And they aren't aware of how they came up with an answer, just like us.
- The Synchrony Budget - I've been working on a blog post on how we should adapt to a partial order of time when writing our programs by default. But it's been languishing in my drafts. This also expresses a similar sentiment.
- Why do economies expand? - This is exactly Clay Christensen's Law of Conservation of Modularity–a lesser known, but arguably more important take on what the landscape of markets look like and behave. Artists and open source developers take note.
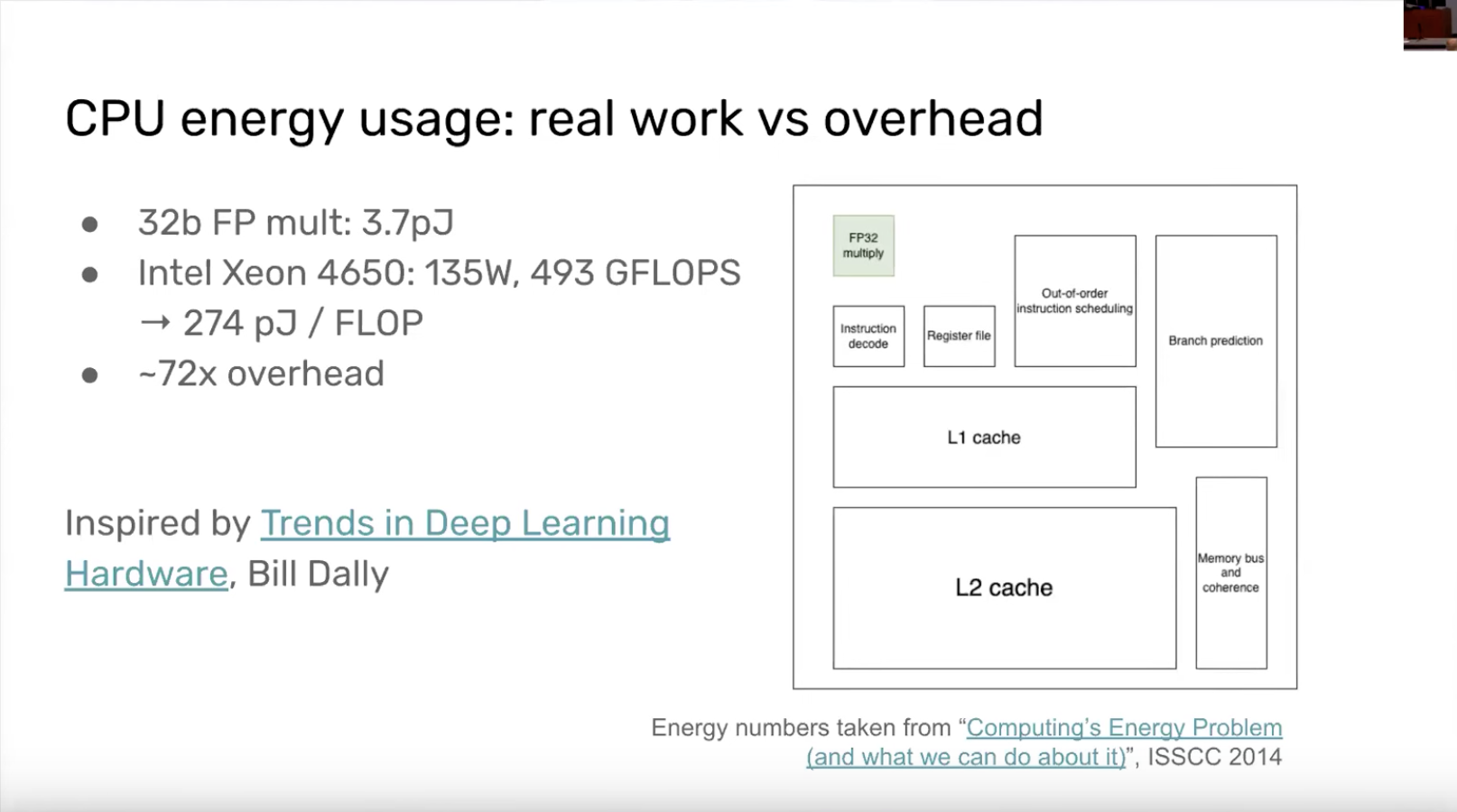
- I want a good parallel computer - The overhead to give the illusion of a single thread on a CPU chip is staggering.
- The Illusion of Acceleration - I found this to be a good study of how people make buying decisions, which is really helpful when you're on the other end, trying to sell people stuff. When you're trying to find Product Market Fit, it can be confusing why people aren't buying, and knowing how people make buying decisions is so helpful.



