Elm should have had Algebraic Effects


While the world has moved on from Elm, I still think about its simplicity a lot and how that was achieved, and what gaps there were in its design. The gaping weakness I'll talk about today was also the result of its strength.
Elm apps have a single unidirectional flow that stemmed from a core design foundation of "the view is a pure function of application state", succinctly written as f(state, msg) = view. This is a great fit if a single user action results in a single message that makes a small state change.
But if a single user action results in multiple messages, or the single message requires multiple side-effects, then the simplicity becomes a hindrance–the developer must now trace multiple cycles through the architecture. It's no longer simple to trace through what the system does in response to a single user action.
If Elm had Algebraic Effects, it would have made it more adaptable to these multi-message processing. In fact, Algebraic Effects as a control flow mechanism, would simplify many other types of more complicated workarounds we see today in other systems.
Elm's Outsized Contribution
Even if Elm isn't very popular language and frontend framework today, it's had a drastic and important influence on web frontend architecture with The Elm Architecture (TEA). After shedding its signals from its Functional Reactive Programming roots, Evan Czapliki (creator of Elm) said this architecture sort of fell into place.
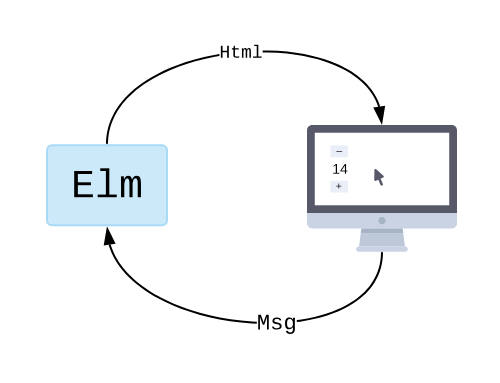
TEA is conceptually simple. Model the view as a pure function of application state. Views can generate messages in response to user actions, like clicks. And based on any messages that come in from the outside, we immutably modify the state. Any state change is reflected by the pure function that transforms state into a view. The state change function is a giant switch statement that routes messages to the appropriate part of the code that makes a small state change.
The entire thing is a unidirectional dataflow. No rat's nest of dependency graphs. No race conditions. It’s easy to keep in your head what's going on at any moment in the lifecycle in response to user input. And The big switch statement to route messages means that you only need to trace a single branch of the pure function to understand what it’s doing.
Compared to the object-orientated Model-View-Controller, the Observer pattern, bidirectional binding in Angular/Backbone/etc, or a pile of event handlers for event callbacks in jQuery, The Elm Architecture was devastatingly simple. In fact, the original React Flex architecture, the subsequent Redux library, and the now standard React useReduce are of the same lineage. They are all unidirectional flows from application state to the view, and they cycle back to state changes in response to user generated events by interacting with the view.
Performing Side Effects
What if you want to perform side effects in your Elm-based web application? Elm is a pure functional language, and in program where the view is a pure function of the application state, how do you fetch from the network or generate random numbers?
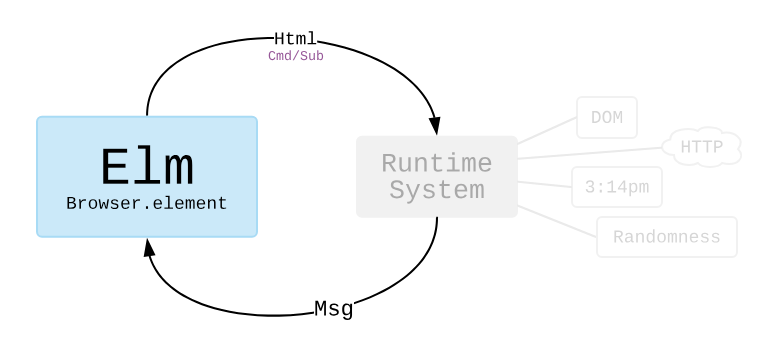
The short answer is, you don't–at least not directly. Instead, you unwind the callstack of your pure function generating the view from application state and return a command (or subscription) back to the runtime (Cmd/Sub in the figure above). The runtime then takes that command and executes it for you, and returns the result back to you as yet another message. You can then handle that message like you would any other in the giant switch statement in your f(state, msg).
The great part of this design is that it keeps the same architecture and model, and repurposes it for running side effects. The bad part of this design is that you need to trace through multiple Cmd/Msg cycles in order to figure out what the program is doing in response to a single user action. That increase in cognitive load can boil over beyond the advantages of TEA in the first place.
How would that happen? It happens when a single user action generates a message that requires multiple side effects to complete. The most familiar way this happens is if there's a button that shows the user a list of blog posts and the number of tweets for that post. In order to do that the application must query the database for blog posts and fetch from a 3rd party API for number of retweets. This is what would happen:
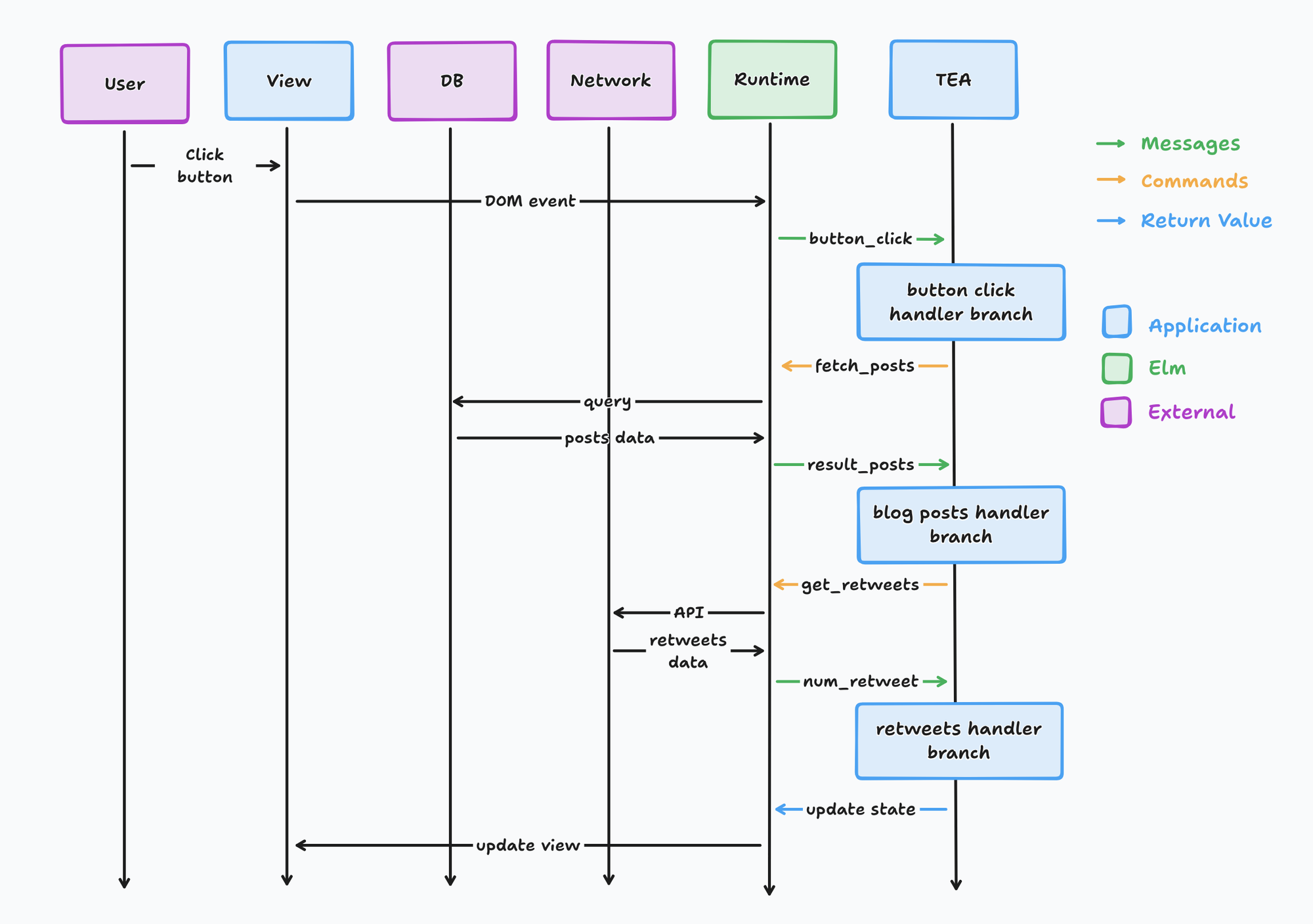
- User clicks the button that generates a button_click message.
- button_click message gets routed by the TEA switch statement to the button_click_handler
- The button_click_handler returns fetch_posts command back to the runtime.
- The runtime fetches posts from the database and sends a result_posts message.
- result_posts message gets routed by the TEA switch statement to the blog_posts_handler branch.
- The blog_post_handler branch returns the get_retweets command back to the runtime.
- The runtime fetches retweet counts from the network API and sends a num_retweets message.
- get_retweets message gets routed by the TEA switch statement to the retweets_handler branch.
- The change in application state then changes the view.
If you skipped all that, that's the point. It was as tedious for me to write it as it would have been for you to read it. But the gist is this:
The logical, linear progression of a computation to handle a single user action is now broken up across multiple branches in a switch statement. Every time you have to cross the boundary to match messages in order to trace program execution, it's overhead in your cognitive load.
What if instead you could fetch posts and retweets and just resume a pure function call where you left off with the results of the side effect. Notice the lines with perform in this listing. That's where the effects are being called. We don't have to break this up into separate branches of the switch statement every time we need to perform a side effect.
-- effect signatures
effect FetchPosts : () -> List { id : String, title : String, body : String }
effect GetRetweetsBulk : List String -> List ( String, Int ) -- (postId, count)
update : Msg -> Model -> Model
update msg model =
case msg of
ClickRefresh ->
handleEffects model <| \resume ->
let
posts = perform (FetchPosts ())
ids = List.map .id posts
pairs = perform (GetRetweetsBulk ids)
dict = Dict.fromList pairs
merged =
List.map
(\p ->
{ id = p.id
, title = p.title
, body = p.body
, retweets = Dict.get p.id dict |> Maybe.withDefault 0
}
)
posts
in
resume { model | posts = merged, loading = False, error = Nothing }
_ ->
modelYou could run the fetching of posts and retweets in parallel, but I kept it sequential to illustrate the resumption of side effect results.
So instead of multiple messages to handle this sequence of computations, we raise effects every time we need the result of a side effect, and resume the computation after we got the side effect result.
This is what Algebraic Effects do.
A short description of Algebraic Effects
Algebraic effects is not too hard to write your head around if you understand a few basic concepts. They're basically a new kind of control flow that can be easily described mechanically to newcomers as resumable exceptions. However, unlike exceptions, they're meant for everyday control flow.
Most developers now are familiar with exceptions. We wrap computation in try/catch block, where the catch block is the exception handlers, in case those handlers need to be invoked by thrown exceptions. Structurally, algebraic effects are no different. We wrap computation in a block with an effect handler that will execute should the computation raise effects.
But exceptions and algebraic effects are different in that we're taught that we shouldn't use exceptions as regular control flow, because they're for exceptional cases. And once an exception is throw, the stack is unwound, and we can never go back to where the exception was raised.
Algebraic effects are different. When an effect is performed (or raised), like exceptions, we start searching up the callstack for a suitable handler for this effect. Once we find the first suitable handler, we can execute that handler to do some side effect. With the side effect result in hand, the handler can decide to do a couple of things:
- Resume the computation with the result one or more times.
- Abort the computation
- Delegate to another handler higher up the call stack.
If the handler resumes the computation, the control flow jumps back to the point of execution right after that effect was raised. To the application developer, performing an effect seems like a simple function call: you raise the effect, you can a value back. However, the differences are:
- The function that raised the effect remains pure. Hence easier to test and easier to reason about.
- A handler can choose to resume multiple times, and computation will resume right after the raised effect with the same call stack every time.
Why would you want to resume a handler multiple times? Maybe the side effect you want is a websocket and you want it to stream results to your program as it gets the data. So the handler would just resume your program at the same spot every time it gets a new piece of data.
If the handler aborts the computation, the control flow throws away all the work it did since it entered the handler. It's as if we never went that way and did any of the work. We resume execution after the handler as if we never executed our computation at all!
There's more to Algebraic Effects, such as how they work under the hood, what they're commonly used for, and their current downsides (it can be slow to look up handlers, but that can be mitigated). Also, what's algebraic about Algebraic Effects? I won't get into any of that for now, but just to say that it would have been a good solution to this problem in Elm.
Designing systems
This kind of control flow is very powerful. Control flow that's typically hard-coded inside language features can now be written with Algebraic Effects, such as:
- Exceptions
- Async/await concurrency
- Generators and Coroutines
- Break/continue in loops
- Returns in nested scopes
- State threading in state monads in pure functional languages
- search and backtracking in logical languages like Prolog
- Transactions, rollbacks, and undos in databases
- I/O and external interactions in pure functional languages
They also replace a lot of the use cases for monads.
So given the option for simplicity of a mental model for a narrow band of use-cases, I can understand why Evan Czapliki wouldn't have implemented it. That said, the simplicity of the mental model didn't end up being a good fit for the situation I often found myself in while building web apps, which was the single-message/multiple-side-effects pattern I outlined above.
Would I have gone ahead and attempted the implementation?
Implementing algebraic effects also would have been hard in the Javascript engine. You can implement single resumption algebraic effects with javascript generators, but not the full-blown multiple resumption algebraic effects. To do so requires delimited continuations to be available by the javascript runtime. Your only other alternative is to recreate the callstack in userland and implement delimited continuations in the Elm runtime on top of the javascript runtime.
Given that Elm is a compiled language, recreating the callstack wouldn't have too too far off the beaten path, everyone else higher in the stack. I do know there are attempts to put delimited continuations in Haskell, and Elm is developed in Haskell–maybe there's a viable path there.
The thing to carefully consider is the downside of algebraic effects. I haven't used them enough to know all the catches, but it does seem to me it can be really easy to write spaghetti code with algebraic effects, where the control flow jumps around. I think it should probably remain a super power for library writers to do what they need to, but then everyday application writers probably should use it judiciously in simple ways.
There's up and coming languages that have algebraic effects if you want to use them in experimental languages, check out Koka and Eff. In more production languages, they're available in Unison and Multicore Ocaml. You can check out more in my previous post.

Let me know if you have other questions.



